



















在了解 Dubbo 的概念以及基础架构之后,可以考虑自己搭个 Demo,运行一下,基本知道是怎么回事。
当然很多小伙伴都有在开发中使用的经验,就没必要再搭建一个 Demo 了,在源码里官方也提供了 Demo,这里直接构建源码阅读环境。
环境准备
Git
Maven
IDEA
ZooKeeper
版本基本上影响不大,这里简单说一下我的版本:
软件
版本
Git
2.34.1
Maven
3.8.4
IntelliJ IDEA
2021.3.1 (Ultimate Edition)
ZooKeeper
3.0.5
Dubbo
3.0.5
Dubbo 选择下载 3.0.5,小伙伴也可以直接使用 Git 命令下载其他版本。
安装 ZooKeeper
使用 Docker 安装 ZooKeeper:
1docker pull zookeeper
启动服务:
1docker run -d --name zookeeper -p 2181:2181 zookeeper:latest
Dubbo 源码构建
构建源码
下载源码完毕后,执行 Maven 命令:
1mv ...
最近使用 Google 的体验越来越差,全都是各种垃圾站点,或者爬虫网站,完全影响了体验。
比如我搜索一个 MethodInterceptor 使用。
全是什么xx 客栈、xxITSxx、xx 编程资料、xx 宝库、小 X 知识网 等等,一堆爬虫网站,其实这个也没什么,重点是里面的信息要么不全,要么排版混乱,举报又没什么用。
那有没有一种方法,可以屏蔽掉这些垃圾站点?
有的:用百度。
当然,对于一些小伙伴,对 Google 情有独钟,那也是有其他方法的,那就是使用 uBlacklist 插件。
安装插件
在 Chrome 商城搜索 uBlacklist
GitHub 下载:https://github.com/iorate/ublacklist
安装订阅
订阅源可以在:https://github.com/wdmpa/content-farm-list 查看
1https://raw.githubusercontent.com/wdmpa/content-farm-list/main/uBlacklist.txt
这个 github 还提供了很多其他地址,都可以慢慢研究:
...
工作笔记
未读在工作中基本上都会使用定时任务,常用的有 Spring 定时框架、Quartz、elastic-job、xxl-job 等。这里说不上框架的好坏,只有适合自己的才是最好的,本文仅从个人角度上谈一谈对定时任务的看法。
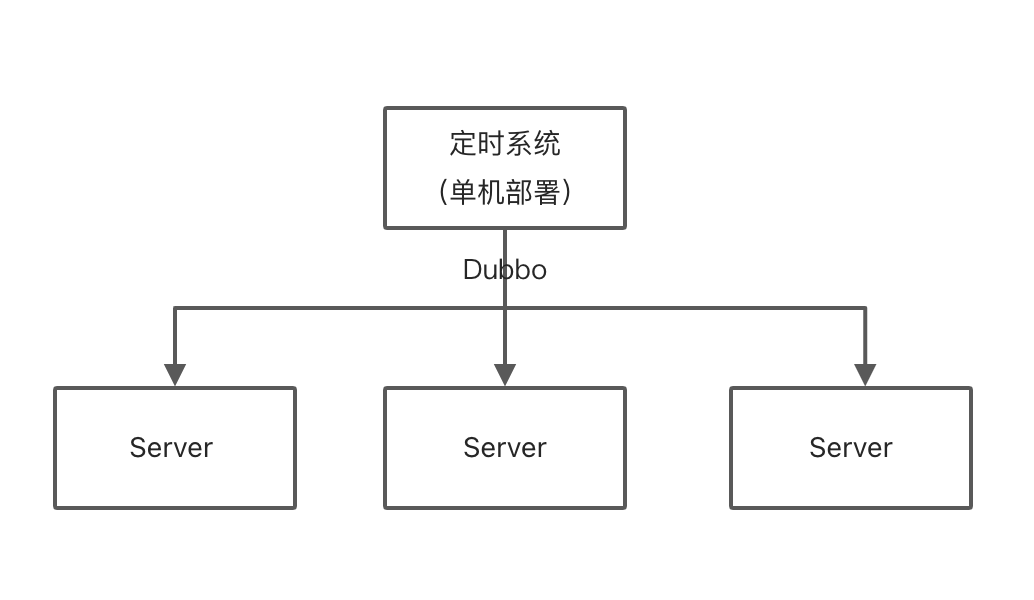
单机定时
单机定时我这里分为纯单机版、 固定 IP 版、分布式锁版、单机调度版,下面从这四个角度来谈一谈他们的实现方式以及当时所在的背景。
纯单机版
顾名思义,就是应用都是单体应用,不存在集群,写一个定时任务就可以了,可以是线程定时调度、也可以是 Spring 定时框架用 @Scheduled注解实现。这种方式在单体应用的极为合适,主要是简单方便。
当然也存在他的弊端,那就是如果我的应用是多机部署的,那就会导致并发冲突。出现问题,解决问题,所以下面三种方式应运而生。
固定 IP 版
就是如果事先知道了机器的 IP 地址,并且基本上 IP 地址也不会变化,只需要在代码中写一个判断逻辑,这样 IP 地址不是当前机器的应用,并不会执行定时任务。
大概逻辑如下:
123456789101112@Componentpublic class ScheduledTask { ...

熟悉我的小伙伴应该知道,我喜欢使用 Markdown 来工作、学习笔记,主要是简洁方便。
并且我是一个坚定地“原生 Markdown 支持者”,什么“所见即所得”都是异端,所以对于 Typora、Notion、Bear、语雀等等一些软件都是略有尝试,但是我始终使用的是 VS Code + Markdown All in One + Markdown Table Marker + Paste Image + One Dark Pro + Project Manager 等组成了一个笔记软件,也确实对我来说 VS Code 只是一个笔记软件。
为什么喜欢原生 Markdown?
因为从最开始写笔记、代码中的 README 时,对其中的语法还花了一段时间来记录,并且总感觉辛辛苦苦写了一篇文章,看着都是文字还有各种语法,在预览的瞬间,有一种成就感(可能有吧)。
后来喜欢写 Hexo 博客,公众号等,都需要支持原生 Markdown,虽然很多“所见即所得”可以复制导出 Markdown,但是在各个平台的兼容性,以及导出的语法并不能够很通用,所以就一直使用原生 Markdown 来记录笔记。
当然 ...
Dubbo
未读相信开发人员对 Dubbo 都不会陌生,工作中对服务间的调用也常常使用 Dubbo 进行 RPC 调用。在开发中一般都是对方提供一个 API 接口,我方引入依赖,加上注解,然后就可以进行通信了。
本着知其所以然的目的,翻查资料,阅读源码,一起深入了解一下 Dubbo 的原理。
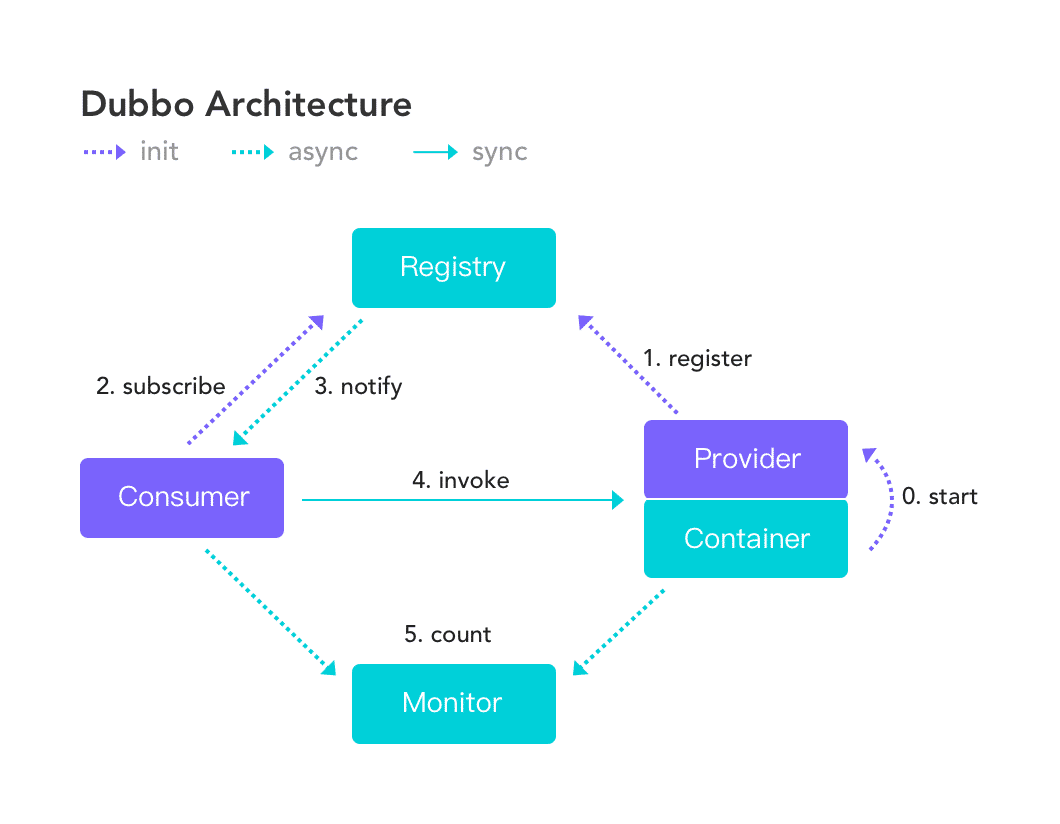
什么是 Dubbo ?
Apache Dubbo 是一款高性能、轻量级的开源服务框架。
Apache Dubbo |ˈdʌbəʊ| 提供了六大核心能力:面向接口代理的高性能 RPC 调用,智能容错和负载均衡,服务自动注册和发现,高度可扩展能力,运行期流量调度,可视化的服务治理与运维。
这六大核心能力分别是:
面向接口代理的高性能 RPC 调用:提供高性能的基于代理的远程调用能力,服务以接口为粒度,为开发者屏蔽远程调用底层细节。
智能负载均衡:内置多种负载均衡策略,智能感知下游节点健康状况,显著减少调用延迟,提高系统吞吐量。
服务自动注册与发现:支持多种注册中心服务,服务实例上下线实时感知。
高度可扩展能力:遵循微内核+插件的设计原则,所有核心能力如 Protocol、Transport、Serializa ...
java
未读前言
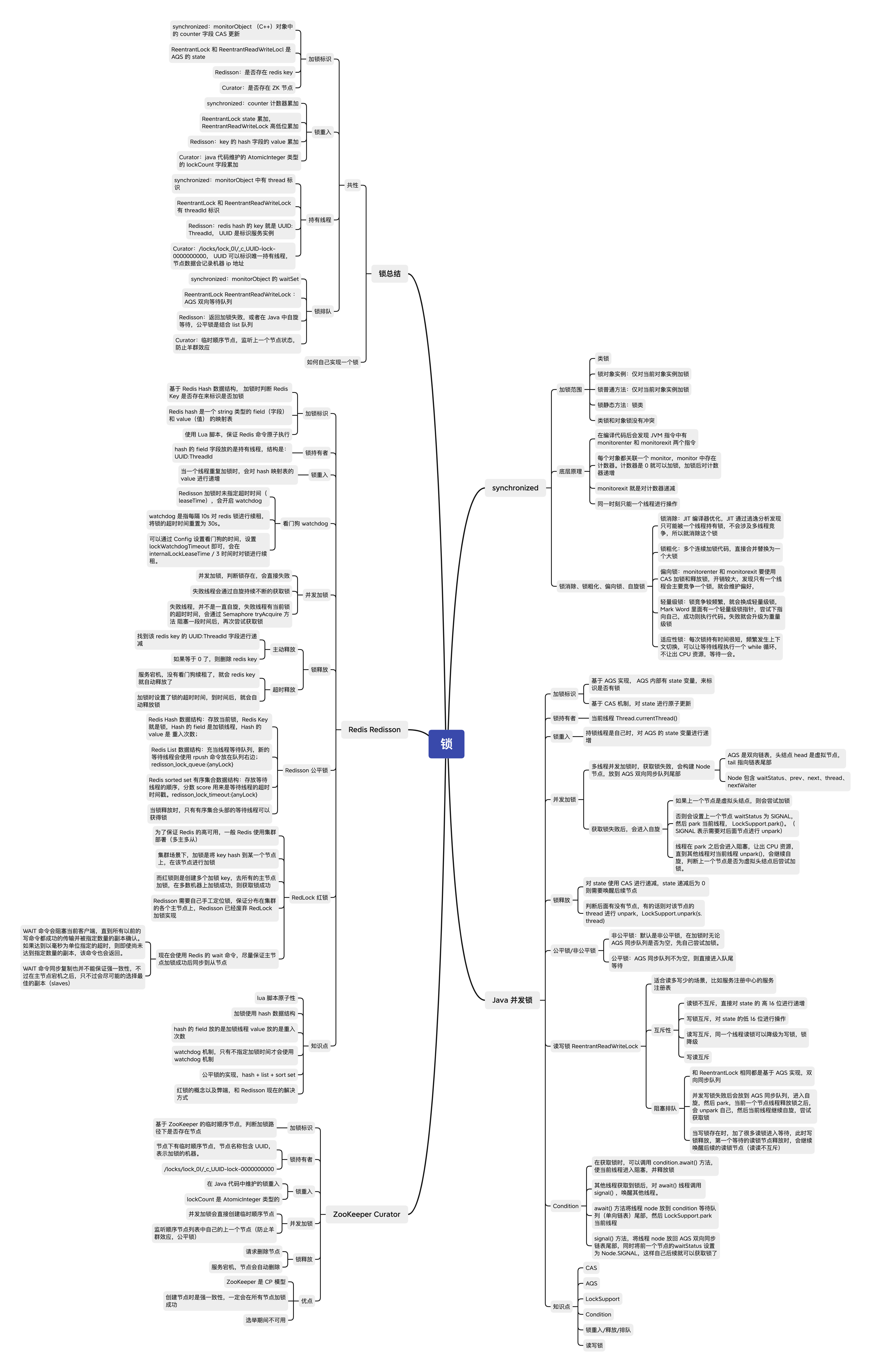
在并发编程中常用到 synchronized 以及 ReentrantLock 锁,在业务开发过程中也可能会用到分布式锁,分布式锁常用框架的就是基于 Redis 实现的分布式锁框架 Redisson 和 基于 Zookeeper 实现的分布式锁框架 Curator。当然,也有其他的锁实现方式,在这里不做介绍。
本文主要是在学习 Java 锁以及分布式锁的源码后,做出的归纳总结。
锁的最基本要素
为什么要使用锁?
关于为什么要使用锁这个问题,答案显而易见:“为了避免多线程并发冲突”。
在多线程中对公共数据的修改,必须要保证只有线程在进行操作。这里的公共数据可以是公共变量,也可以是数据库中的一行数据。
锁的基本要素
知道为什么要加锁之后,就可以得出加锁的基本要素:
锁标志:怎么样才算加锁成功?
锁持有者:是哪个线程加的锁?
锁重入:自己加了锁之后,再次加锁?
锁并发:并发加锁失败的线程该怎么办?
锁释放:用完锁,该怎么释放?
简单来说应该就是这些要素,遗漏之处,欢迎补充。
加锁标志
加锁标志,就是需要一个标志来表示是否加锁成功,并且这个加锁标志要保证原子性。
synchro ...

前言
如果不是踩到坑,我估计到现在还不知道时间字段会四舍五入。
背景
通过 Java 代码获取当日最大时间,然后存入数据库,数据库表字段格式 datetime 保留 0 位。
1now.with(LocalTime.MAX)
小小的一行代码,获取今天的最大日期。
到数据库一看,好家伙,竟然存了第二天的时间。
看着样子是四舍五入了!
模拟测试
执行之后,看一下日志:
使用的是 2021-09-28T23:59:59.999999999,但是很奇怪的是数据库存储的是 2021-09-29 00:00:00。
直接使用 SQL 试一试:
这…… 果然是四舍五入了。
换成 MariaDB 试试!
docker pull mariadb
docker run -d --name mariadb -p 33306:33306 -e “MYSQL_ROOT_PASSWORD=root” mariadb
docker exec -it mariadb bash
MariaDB 是直接舍弃多余位数的!
结论
MySQL 时间如果传入的值超过精度范围,会进行四舍五入。
MariaDB 时间 ...

前言
最近遇到一个小伙伴问前端枚举转换问题,才意识到可以通过转换器(Converter)自动将前端传入的字段值使用枚举接收。
我自己捣鼓了一番,现在记录笔记分享一下!有兴趣的小伙伴可以自己尝试一下!
这里使用的是 MyBatis-Plus 和 SpringBoot 2.3.4.RELEASE
实现过程
配置转换器
123456789101112131415161718192021222324252627282930/** * @author liuzhihang * @date 2021/8/31 16:29 */@Configurationpublic class WebConfig implements WebMvcConfigurer { @Override public void addFormatters(FormatterRegistry registry) { registry.addConverterFactory(new ConverterFactory<Object, BaseEnum>() { ...

前言
近期在 Mapper 中写了个方法重载,然后死活查不到正确结果,最终灵机一动,想到是不是因为重载,然后我 Shift + F6 把重载方法名字改了一下!结果,显而易见,重载的那个方法也一块改了。再次躺坑!
背景
以下为模式测试数据
MySQL 表
Mapper
如果看到这里,已经发现了问题,并知道原因,那可以直接跳过,进行三连即可。
当然,在 Mapper.xml 这么写,会提示错误(插件功能)
Junit
执行结果是:
sum=1500 sumWithTime=1500
这就神奇了,没有报错,结果竟然是相同的。
版本依赖
12345<dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.1.2</version></dependency>
mybatis-plus-boot-start ...

工作笔记
未读前言
在 JDK 中有很多锁,包括 synchronized、ReentrantLock、ReentrantReadWriteLock、锁的使用场景也分很多种,下面看一下对加锁优化的小技巧。
以下内容为个人学习笔记。
并发修改标志位
优先使用 volatile;
比如分布式服务注册中心的优雅停机,因为 volatile 就可以保证可见性。而不必使用 synchronized
数值递增
优先使用 Atomic 原子类;
CAS 无锁化操作,比如分布式服务注册中心的心跳次数维护;
维护线程副本
使用 ThreadLocal
在分布式存储系统使用 ThreadLocal 维护每个线程自己的 txid。
读多写少
使用读写锁 ReentrantReadWriteLock。
比如分布式服务注册中心的服务注册表注册和读取。
尽量减少锁占用时间
加锁范围尽量小,加锁时只操作内存数据,对数据库、磁盘 IO 操作最好不要使用锁。
比如分布式存储是通 edits log 的分段加锁机制。
尽可能减少对数据加锁的力度,分段锁
一份数据包含多个子数据时,对子数据分开加锁,用来替换对整个大的数据进行加锁。
...
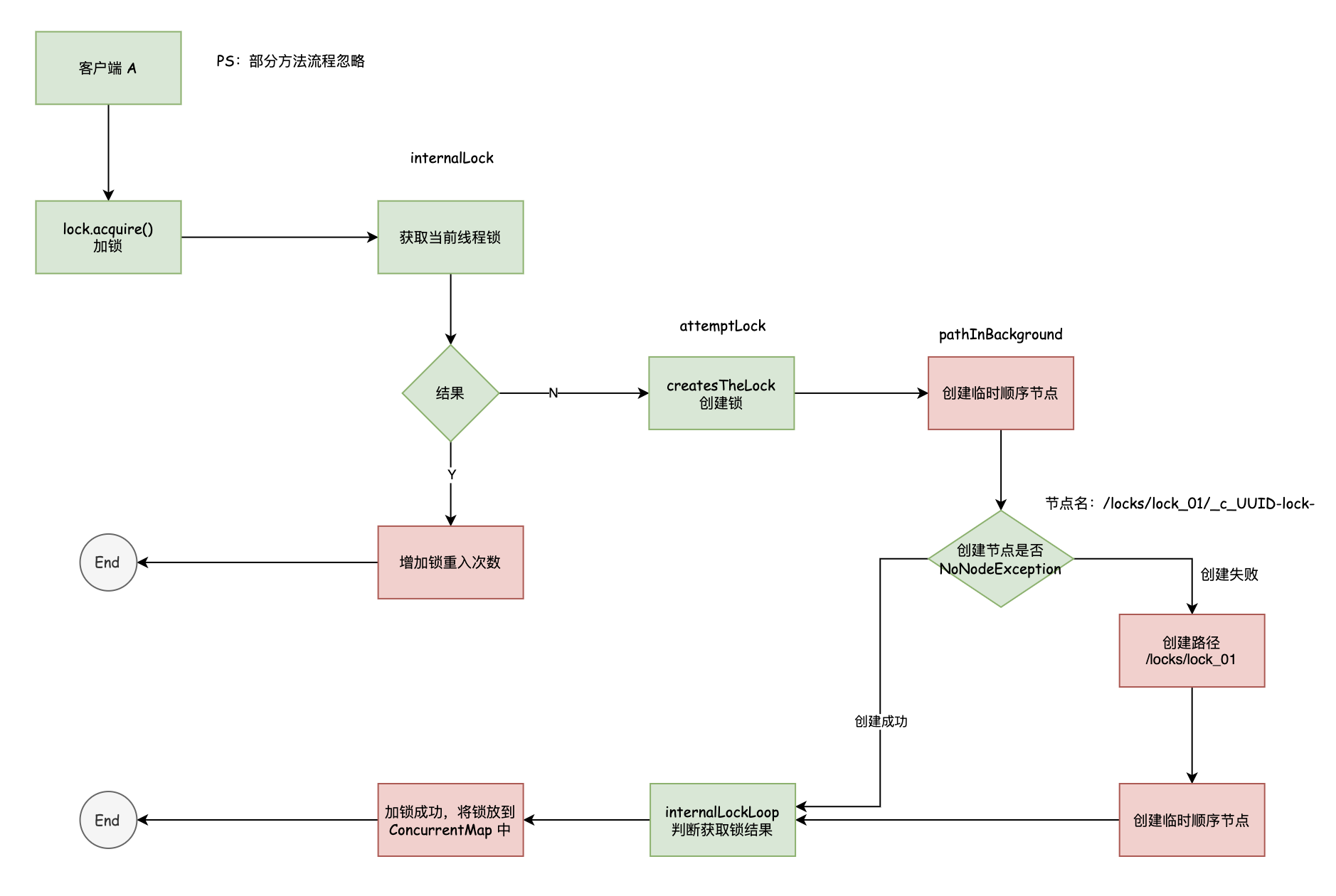
前言
Curator 同样支持分布式读写锁 和联锁,只需要使用 InterProcessReadWriteLock 即可,来一起看看它的源码以及实现方式。
使用方式
1234567891011121314151617181920212223public class CuratorDemo { public static void main(String[] args) throws Exception { String connectString = "127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183"; RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); CuratorFramework client = CuratorFrameworkFactory .builder() .connectString(connectStr ...
前言
分布式信号量,之前在 Redisson 中也介绍过,Redisson 的信号量是将计数维护在 Redis 中的,那现在来看一下 Curator 是如何基于 ZooKeeper 实现信号量的。
使用 Demo
12345678910111213141516171819202122232425262728293031323334353637public class CuratorDemo { public static void main(String[] args) throws Exception { String connectString = "127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183"; RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3); CuratorFramework client = CuratorFrameworkFactory ...



