前言
大家都经常使用 IDEA 进行开发,肯定会使用一些 IDEA 插件,我之前也写过两个插件,不过已经很久没有更新了,就让它先放着吧!
那小伙伴你是否想亲手写一个插件,或者你是否有一些插件的想法,但是找不到插件。那就自己实现一个吧!
创建项目
使用 Gradle 创建
写插件,先从创建项目开始:
File -> New -> Project...
这里使用 Gradle,其中 Java 已经默认选中,咱们再额外选择 IntelliJ Platform Plugin。
点击 Next ,然后填写项目名称,路径等选项。
项目结构
build.gradle 为项目配置文件。
resources/META-INF/plugin.xml 为插件配置文件。
使用 GitHub 模版
访问 https://github.com/JetBrains/intellij-platform-plugin-template
点击 Use this template 创建模版。
Clone 项目到自己本地。
注:模版生成的项目是使用的 Kotlin,所以这里使用的第一种 ...

前言
在看完 ReentrantLock 之后,在高并发场景下 ReentrantLock 已经足够使用,但是因为 ReentrantLock 是独占锁,同时只有一个线程可以获取该锁,而很多应用场景都是读多写少,这时候使用 ReentrantLock 就不太合适了。读多写少的场景该如何使用?在 JUC 包下同样提供了读写锁 ReentrantReadWriteLock 来应对读多写少的场景。
介绍
支持类似 ReentrantLock 语义的 ReadWriteLock 的实现。
具有以下属性:
获取顺序
此类不会将读取优先或写入优先强加给锁访问的排序。但是,它确实支持可选的公平 策略。
支持公平模式和非公平模式,默认为非公平模式。
重入
允许 reader 和 writer 按照 ReentrantLock 的样式重新获取读锁或写锁。在写线程释放持有的所有写锁后,reader 才允许重入使用它们。此外,writer 可以获取读锁,但反过来则不成立。
锁降级
重入还允许从写锁降级为读锁,通过先获取写锁,然后获取读锁,最后释放写锁的方式降级。但是,从读锁升级到写锁是不可 ...
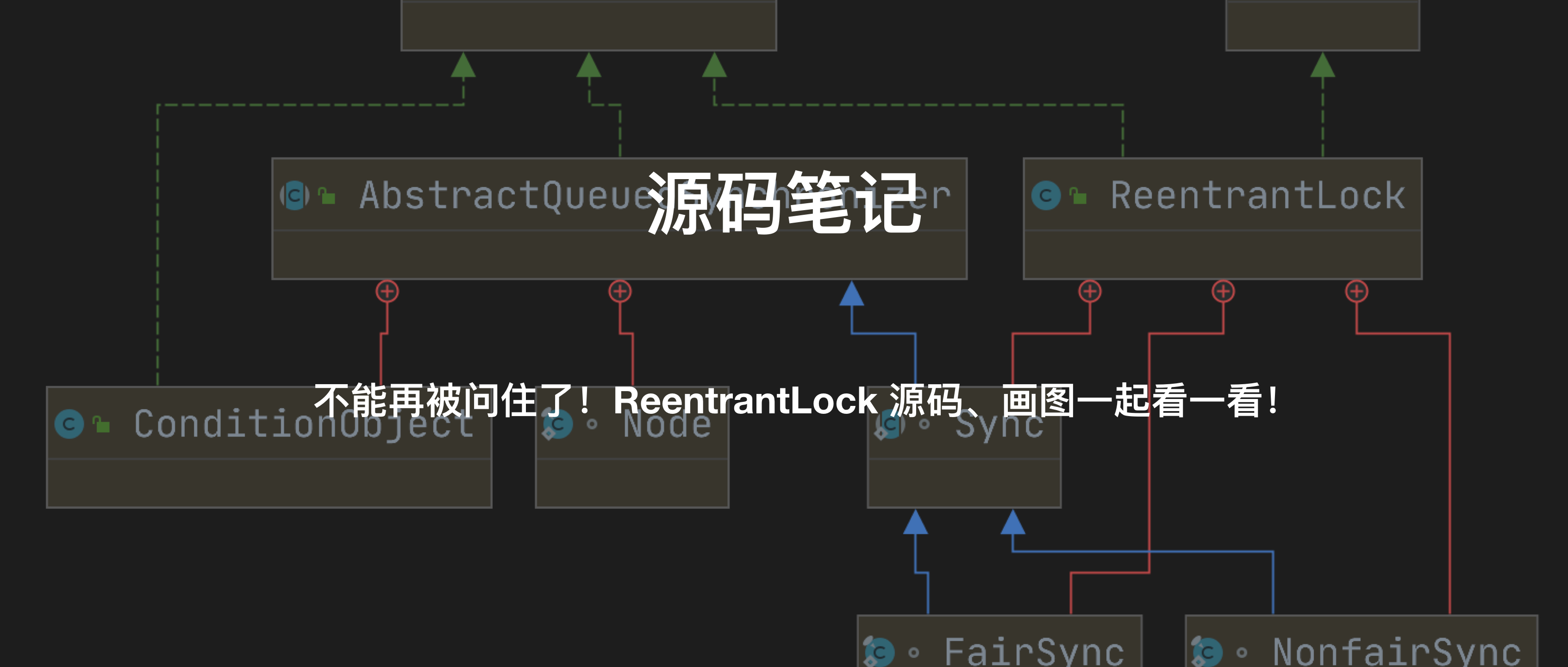
在阅读完 JUC 包下的 AQS 源码之后,其中有很多疑问,最大的疑问就是 state 究竟是什么含义?并且 AQS 主要定义了队列的出入,但是获取资源、释放资源都是交给子类实现的,那子类是怎么实现的呢?下面开始了解 ReentrantLock。
介绍
一个可重入的互斥锁与隐式监视器锁synchronized具有相同的基本行为和语义,但功能更强大。
具有以下特征:
互斥性:同时只有一个线程可以获取到该锁,此时其他线程请求获取锁,会被阻塞,然后被放到该锁内部维护的一个 AQS 阻塞队列中。
可重入性:维护 state 变量,初始为 0,当一个线程获取到锁时,state 使用 cas 更新为 1,本线程再次申请获取锁,会对 state 进行 CAS 递增,重复获取次数即 state,最多为 2147483647 。试图超出此限制会从锁定方法抛出 Error。
公平/非公平性:在初始化时,可以通过构造器传参,指定是否为公平锁,还是非公平锁。当设置为 true 时,为公平锁,线程争用锁时,会倾向于等待时间最长的线程。
基本使用
12345678910111213class X
...
又要开发新项目了,还是创建新项目,怎么办?老大说按照 xxx 项目的结构创建一个新项目就可以了。
在工作中经常有新项目需要创建,此时就会有三种常用的方式
CC 大法 新建项目,然后找到之前的各种工具类,复制粘贴进来,此时还不一定能跑起来,然后再进行各种调试。
CD 大法 复制老项目,然后改 module 名字,依赖名字,删除老代码,当然也不一定能跑起来,此时再进行各种调试。
当然,这里肯定不是使用这两种办法,下面咱们介绍一种更简洁的方式,使用 maven archetype 生成项目模版,一键创建项目。
Action!!!
什么是 Archetype ?
简而言之,Archetype 是 Maven 项目模板工具箱。
An archetype is defined as an original pattern or model from which all other things of the same kind are made.
原型被定义为原始样式或模型,从中可以制成所有其他同类项目。
官方解释,简洁明了,就是使用已有的项目,生成一个模版。以后使用这个模版就可以快速生成 ...
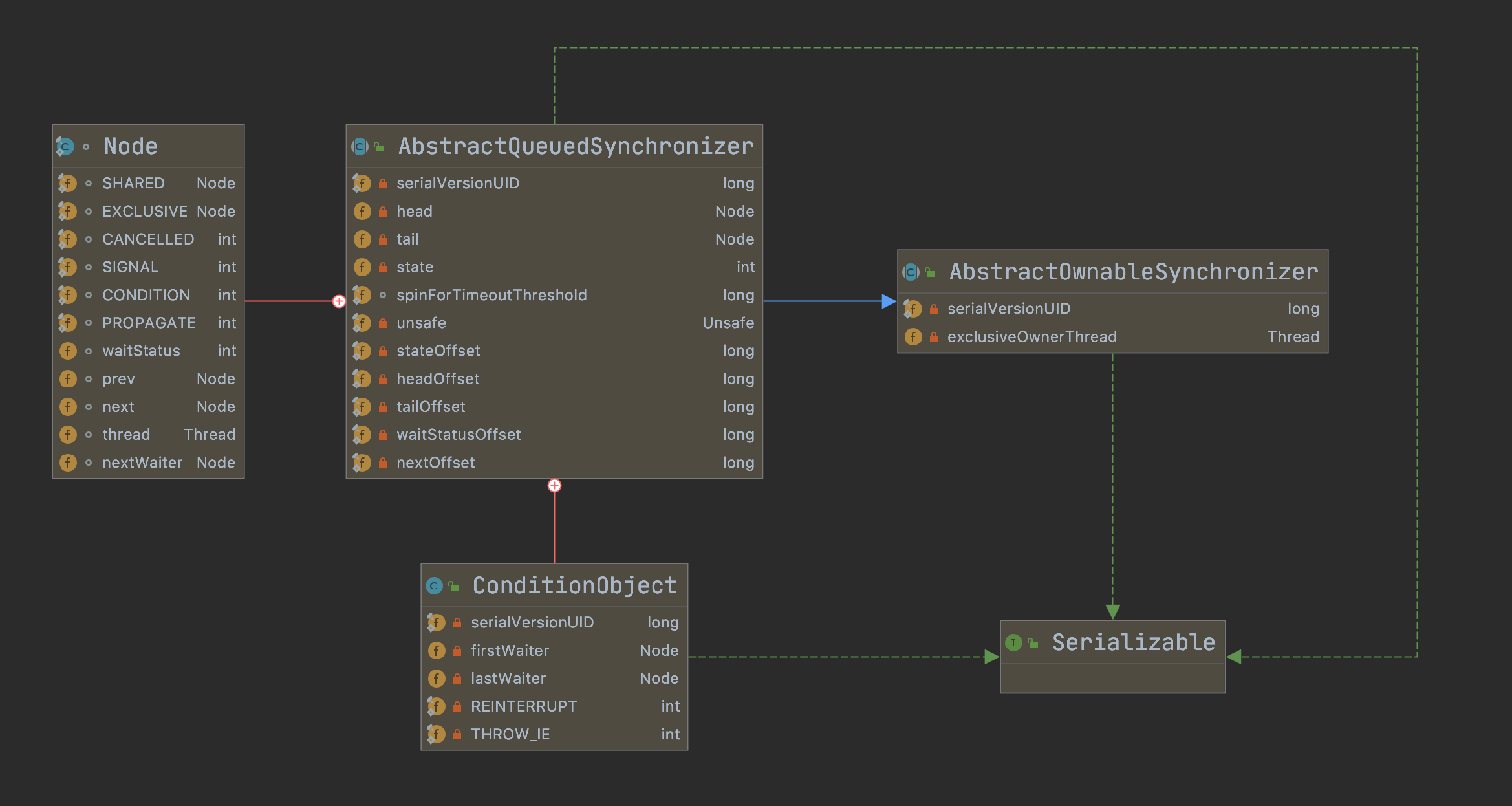
AbstractQueuedSynchronizer 抽象队列同步器,简称 AQS 。是在 JUC 包下面一个非常重要的基础组件,JUC 包下面的并发锁 ReentrantLock CountDownLatch 等都是基于 AQS 实现的。所以想进一步研究锁的底层原理,非常有必要先了解 AQS 的原理。
介绍
先看下 AQS 的类图结构,以及源码注释,有一定的大概了解之后再从源码入手,一步一步研究它的底层原理。
" 源码注释
提供了实现阻塞锁和相关同步器依靠先入先出(FIFO)等待队列(信号量,事件等)的框架。 此类中设计了一个对大多数基于 AQS 的同步器有用的原子变量来表示状态(state)。 子类必须定义 protected 方法来修改这个 state,并且定义 state 值在对象中的具体含义是 acquired 或 released。 考虑到这些,在这个类中的其他方法可以实现所有排队和阻塞机制。 子类可以保持其他状态字段,但只能使用方法 getState 、setState 和 compareAndSetState 以原子方式更新 state 。
子类应被定义 ...
LockSupport 是 JUC 中常用的一个工具类,主要作用是挂起和唤醒线程。在阅读 JUC 源码中经常看到,所以很有必要了解一下。
介绍
基本线程阻塞原语创建锁和其他同步类。Basic thread blocking primitives for creating locks and other synchronization classes.
LockSupport 类每个使用它的线程关联一个许可(在意义上的Semaphore类)。 如果许可可用,调用 park 将立即返回,并在此过程中消费它; 否则可能阻塞。如果许可不是可用,可以调用 unpark 使得许可可用。(但与Semaphore不同,许可不能累积。最多有一个。)
方法 park 和 unpark 提供了阻塞的有效手段和解锁线程不会遇到死锁问题,而 Thread.suspend 和 Thread.resume 是不能用于这种目的:因为许可的存在,一个线程调用 park 和另一个线程试图 unpark 它之间的竞争将保持活性。 此外,如果调用者线程被中断,park 将返回,并且支持设置超时。 该 park 方法 ...
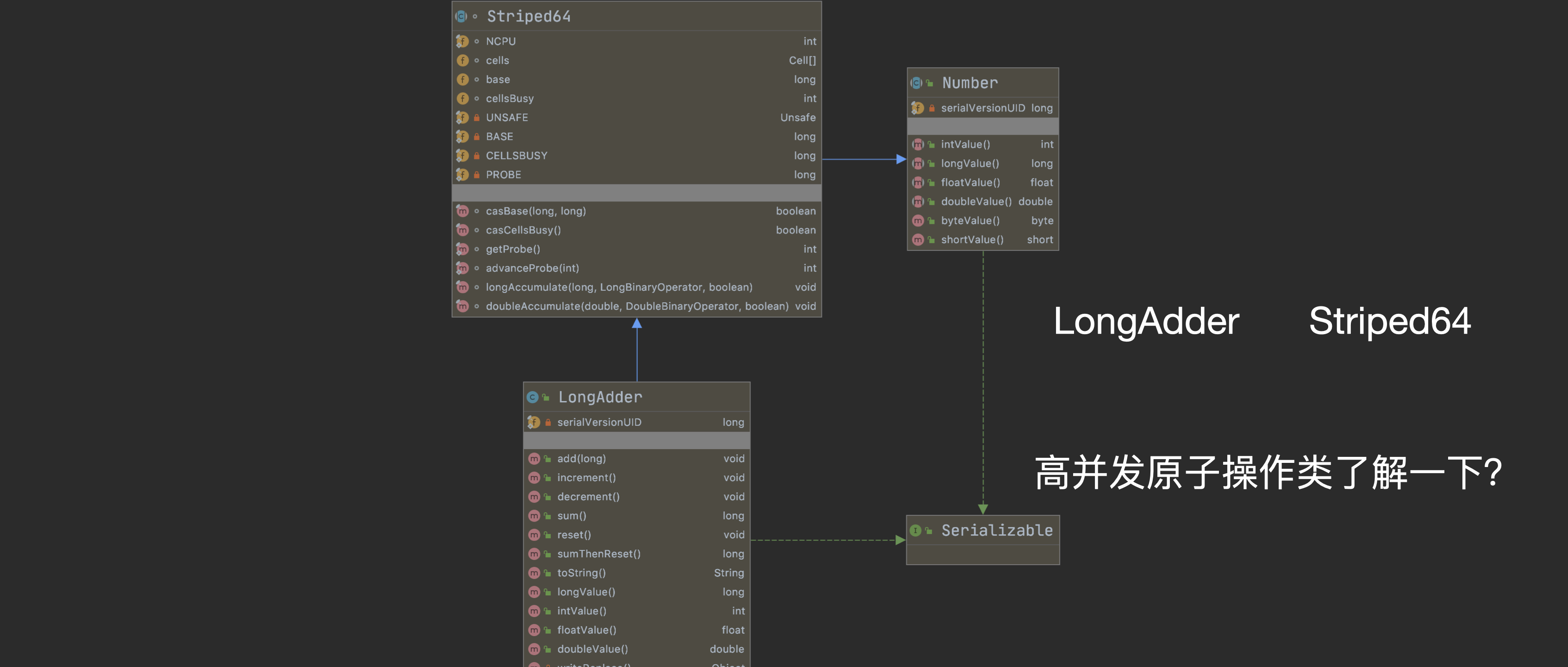
在介绍 AtomicInteger 时,已经说明在高并发下大量线程去竞争更新同一个原子变量时,因为只有一个线程能够更新成功,其他的线程在竞争失败后,只能一直循环,不断的进行 CAS 尝试,从而浪费了 CPU 资源。而在 JDK 8 中新增了 LongAdder 用来解决高并发下变量的原子操作。下面同样通过阅读源码来了解 LongAdder 。
介绍
一个或多个变量共同维持初值为 0 总和。 当跨线程竞争更新时,变量集可以动态增长以减少竞争。 方法 sum 返回当前变量集的总和。
当多个线程更新时,这个类是通常优选 AtomicLong ,比如用于收集统计信息,不用于细粒度同步控制的共同总和。 在低更新竞争,这两个类具有相似的特征。 但在高更新竞争时,使用 LongAdder 性能要高于 AtomicLong,同样要消耗更高的空间为代价。
LongAdder 继承了 Striped64,内部维护一个 Cells 数组,相当于多个 Cell 变量, 每个 Cell 里面都有一个初始值为 0 的 long 型变量。
源码分析
Cell 类
Cell 类 是 Striped64 的静态内 ...
前言
业务开发中经常使用 ThreadLocal 来存储用户信息等线程私有对象… ThreadLocal 内部构造是什么样子的?为什么可以线程私有?常说的内存泄露又是怎么回事?
公众号:liuzhihangs ,记录工作学习中的技术、开发及源码笔记;时不时分享一些生活中的见闻感悟。欢迎大佬来指导!
介绍
ThreadLocal 类提供了线程局部变量。和正常对象不同的是,每个线程都可以访问 get()、set() 方法,获取独属于自己的副本。 ThreadLocal 实例通常是类中的私有静态字段,并且其状态和线程关联。
每个线程都保持对其线程局部变量副本的隐式引用,只要线程是活动的并且 ThreadLocal 实例访问; 一个线程消失之后,所有的线程局部实例的副本都会被垃圾回收(除非存在对这些副本的其他引用)。
使用
有这么一种使用场景,收到 web 请求,先进行 token 验证,而这个 token,可以解析出用户 user 的信息。所以我这边一般是这样使用的:
自定义注解, @CheckToken , 标识该方法需要校验 token。
在 Interceptor(拦截器)中 ...

前言
JUC包下大量使用了CAS,工作和面试中也经常遇到CAS,包括说到乐观锁,也不可避免的想起CAS,那CAS究竟是什么?
概念
说到CAS,基本上都会想到乐观锁、AtomicInteger、Unsafe …
当然也有可能啥也没想到!
不管你们怎么想, 我第一印象是乐观锁,毕竟做交易更新交易状态经常用到乐观锁,就自然想到这个SQL:
123update trans_order set order_status = 1 where order_no = 'xxxxxxxxxxx' and order_status = 0;
其实就是 set和where里面都携带order_status。
那什么是CAS?
CAS就是Compare-and-Swap,即比较并替换,在并发算法时常用,并且在JUC(java.util.concurrent)包下很多类都使用了CAS。
非常常见的问题就是多线程操作i++问题。一般解决办法就是添加 synchronized 关键字修饰,当然也可以使用 AtomicInteger 代码举例如下:
12345678910111213141 ...
前言
在阅读HashMap源码时,会发现在HashMap中使用了红黑树,所以需要先了解什么是红黑树,以及其原理。从而再进一步阅读HashMap中的链表到红黑树的转换,红黑树的增删节点等。
什么是红黑树?
在HashMap中是怎么应用的?
什么是红黑树?
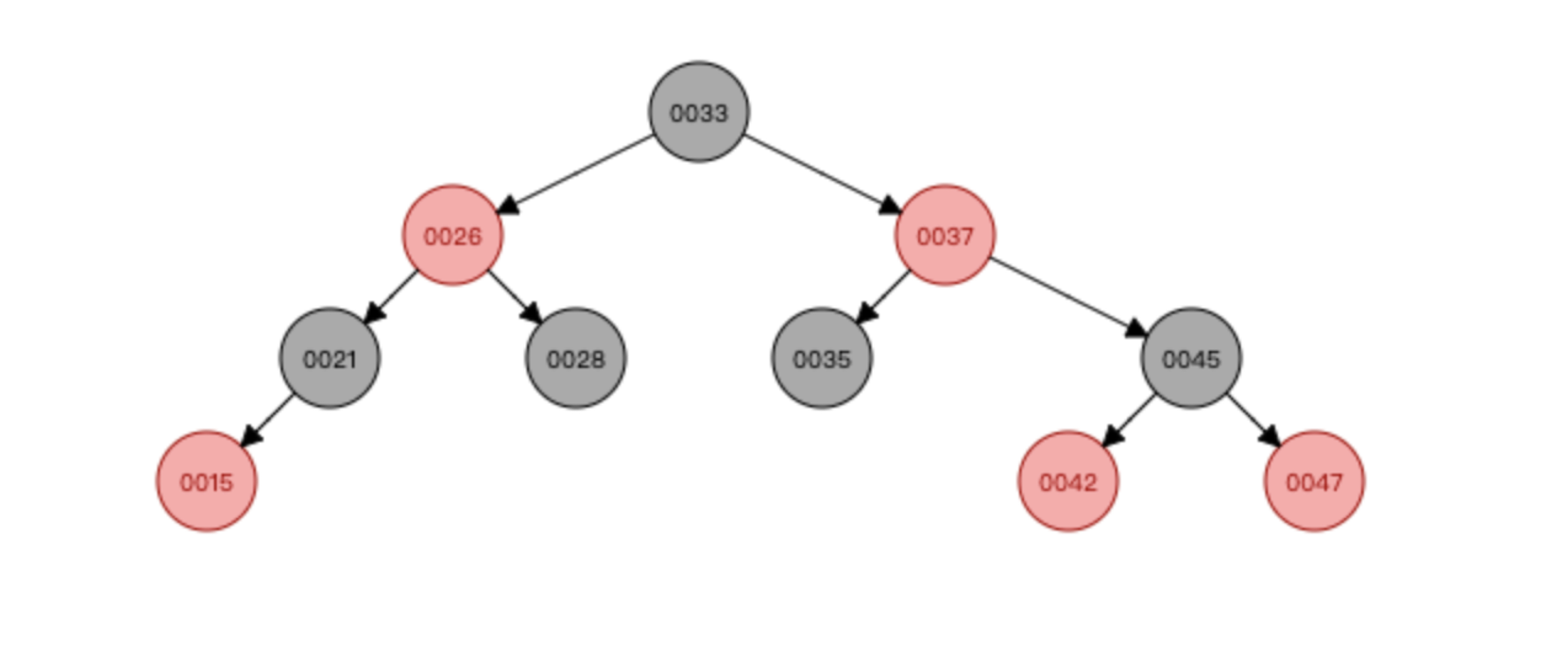
红黑树(英语:Red–black tree)是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。它在1972年由鲁道夫·贝尔发明,被称为"对称二叉B树",它现代的名字源于Leo J. Guibas和Robert Sedgewick于1978年写的一篇论文。红黑树的结构复杂,但它的操作有着良好的最坏情况运行时间,并且在实践中高效:它可以在O(logN)时间内完成查找、插入和删除,这里的n是树中元素的数目。
红黑树的性质
红黑树是每个节点都带有颜色属性的二叉查找树,颜色为红色或黑色。在二叉查找树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:
节点是红色或黑色。
根是黑色。
所有叶子都是黑色(叶子是NIL节点)。
每个红色节点必须有两个黑色的子节点。(从 ...
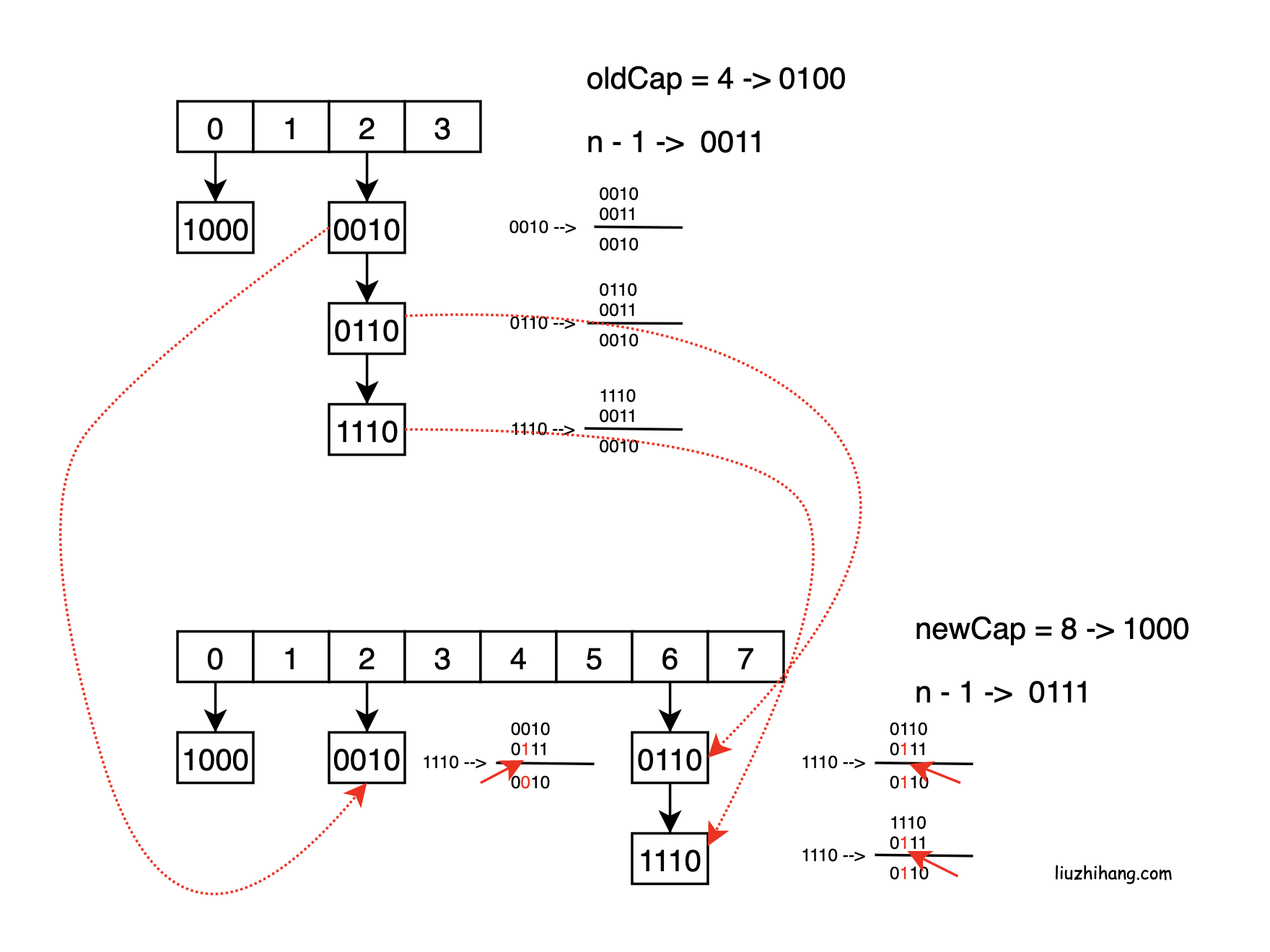
描述下HashMap put(k,v)的流程?
它的扩容流程是怎么样的?
HashMap put(k,v)流程
通过hash(key方法)获取到key的hash值
调用put方法, 将value存放到指定的位置
根据hash值确定当前key所在node数组的索引 (n - 1) & hash
如果node[i]==null 则直接创建新数组
如果node[i]!=null
判断 当前node的头结点的 hash和key是否都相等, 相等则需要操作的就是该node
判断当前节点是否为TreeNode,对TreeNode进行操作,并返回结果e
如果是链表则遍历链表,key存在则返回节点e,不存在则赋值
判断节点e有没有被赋值,覆盖旧值
hashMap size进行加1,同时判断v新size是否大于扩容阈值从而判断是否需要扩容
123public V put(K key, V value) { return putVal(hash(key), key, value, false, true);}
12345678910111213141 ...

HashMap初始化参数都是什么?默认是多少?
为什么建议初始化设置容量?
tableSizeFor方法是做什么的?
如何获取到一个key的hash值?及计算下标?
HashMap初始化参数都是什么?默认是多少?
HashMap初始化参数分别是初始容量和负载因子。
初始容量(threshold):默认 16, 必须是2的幂, 最大容量为 1 << 30
负载因子(loadFactor):是指哈希表的负载因子,当哈希表的长度大于capacity * loadFactor时会进行扩容,默认 0.75f
为什么建议初始化设置容量
这块涉及到HashMap的扩容, 在阿里巴巴Java开发手册中已经说明了原因。主要是为了减少频繁的扩容造成的资源损耗。
tableSizeFor方法是做什么的?
初始化HashMap时, 如果传入初始容量, 在初始化时会调用 tableSizeFor(initialCapacity) 方法寻找大于等于当前值的下一个2的幂值.
代码如下:
1234567891011static final int tableSizeFor(int cap)
...




