在介绍 AtomicInteger 时,已经说明在高并发下大量线程去竞争更新同一个原子变量时,因为只有一个线程能够更新成功,其他的线程在竞争失败后,只能一直循环,不断的进行 CAS 尝试,从而浪费了 CPU 资源。而在 JDK 8 中新增了 LongAdder 用来解决高并发下变量的原子操作。下面同样通过阅读源码来了解 LongAdder 。
介绍 一个或多个变量共同维持初值为 0 总和。 当跨线程竞争更新时,变量集可以动态增长以减少竞争。 方法 sum 返回当前变量集的总和。
当多个线程更新时,这个类是通常优选 AtomicLong ,比如用于收集统计信息,不用于细粒度同步控制的共同总和。 在低更新竞争,这两个类具有相似的特征。 但在高更新竞争时,使用 LongAdder 性能要高于 AtomicLong,同样要消耗更高的空间为代价。
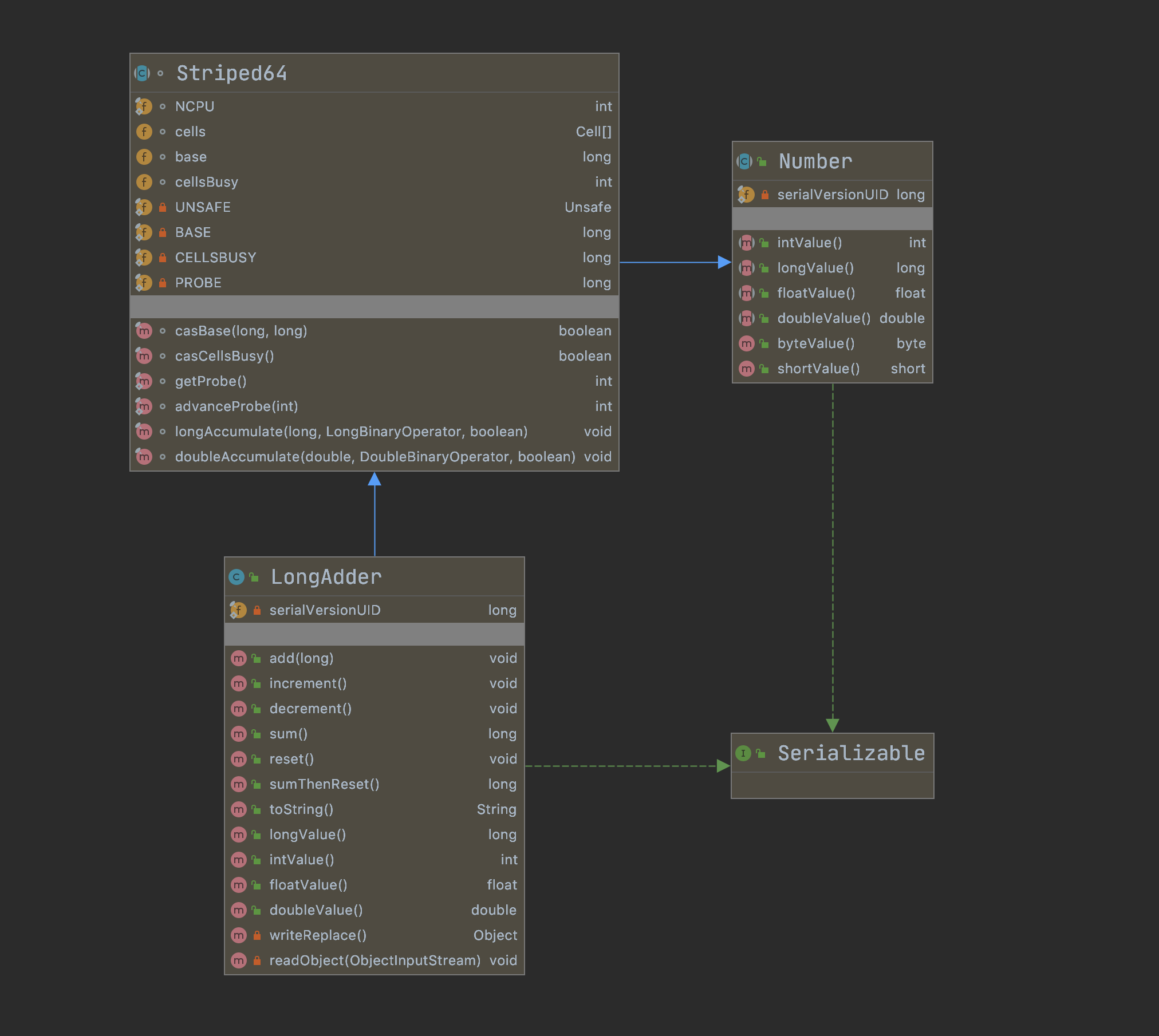
LongAdder 继承了 Striped64,内部维护一个 Cells 数组,相当于多个 Cell 变量, 每个 Cell 里面都有一个初始值为 0 的 long 型变量。
源码分析 Cell 类 Cell 类 是 Striped64 的静态内部类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @sun .misc.Contended static final class Cell { volatile long value; Cell(long x) { value = x; } final boolean cas (long cmp, long val) { return UNSAFE.compareAndSwapLong(this , valueOffset, cmp, val); } private static final sun.misc.Unsafe UNSAFE; private static final long valueOffset; static { try { UNSAFE = sun.misc.Unsafe.getUnsafe(); Class<?> ak = Cell.class; valueOffset = UNSAFE.objectFieldOffset (ak.getDeclaredField("value" )); } catch (Exception e) { throw new Error (e); } } }
Cell 使用 @sun.misc.Contended 注解。
内部维护一个被 volatile 修饰的 long 型 value 。
提供 cas 方法,更新value。
其中 @sun.misc.Contended 注解作用是为了减少缓存争用。什么是缓存争用,这里只做下简要介绍。
伪共享http://openjdk.java.net/jeps/142
Striped64 核心属性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 abstract class Striped64 extends Number { static final int NCPU = Runtime.getRuntime().availableProcessors(); transient volatile Cell[] cells; transient volatile long base; transient volatile int cellsBusy; }
Striped64 类主要提供以下几个属性:
NCPU:CPU 的数量,以限制表大小。
cells:Cell[] cell 数组,当非空时,大小是 2 的幂。
base:long 型,Base 值,在无争用时使用,表初始化竞赛期间的后备。使用 CAS 更新。
cellsBusy:调整大小和创建Cells时自旋锁(通过CAS锁定)使用。
下面看是进入核心逻辑:
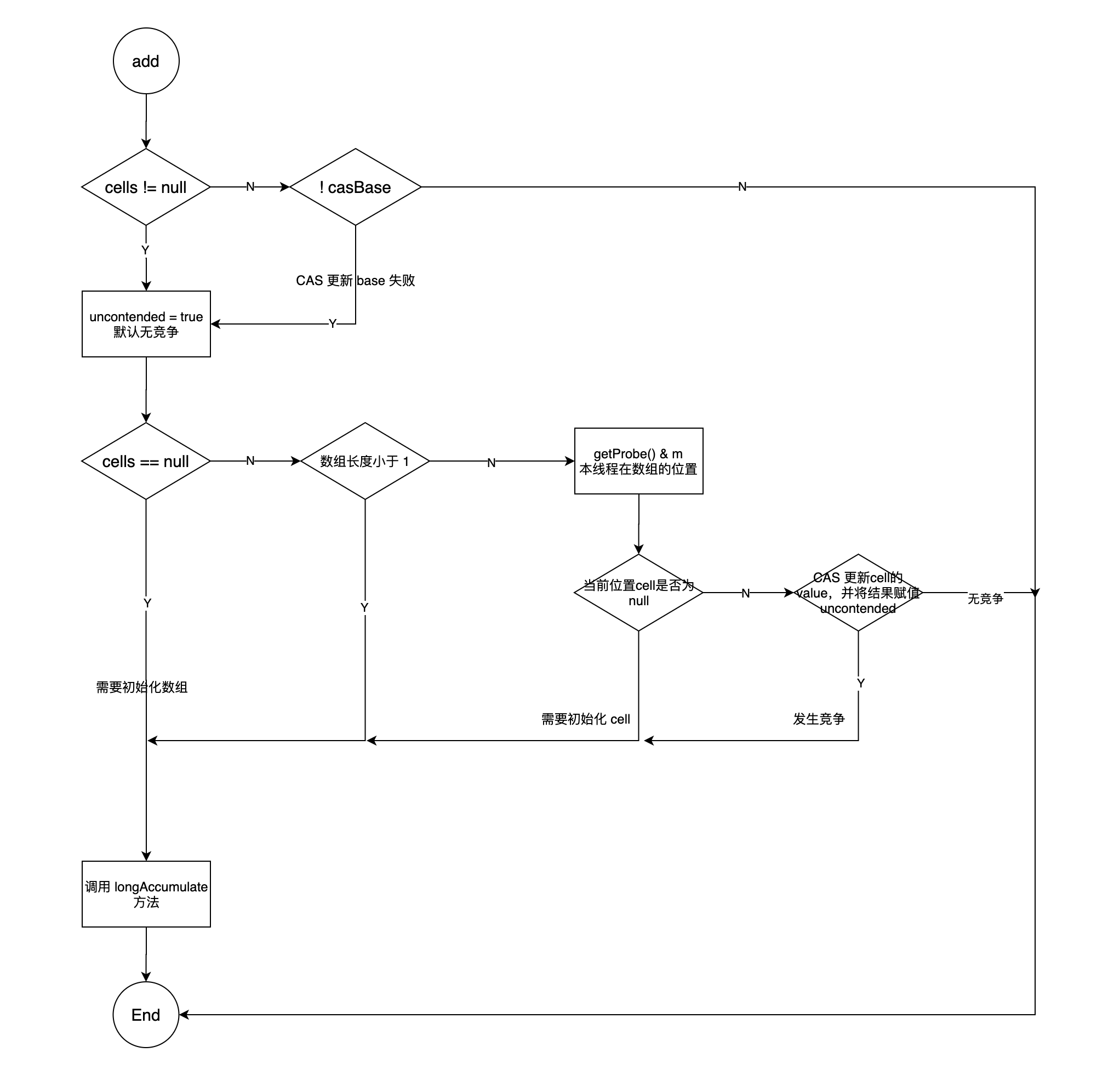
LongAdder#add 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class LongAdder extends Striped64 implements Serializable { public void add (long x) { Cell[] as; long b, v; int m; Cell a; if ((as = cells) != null || !casBase(b = base, b + x)) { boolean uncontended = true ; if (as == null || (m = as.length - 1 ) < 0 || (a = as[getProbe() & m]) == null || !(uncontended = a.cas(v = a.value, v + x))) longAccumulate(x, null , uncontended); } } }
1 2 3 4 5 6 7 8 9 10 11 12 abstract class Striped64 extends Number { final boolean casBase (long cmp, long val) { return UNSAFE.compareAndSwapLong(this , BASE, cmp, val); } static final int getProbe () { return UNSAFE.getInt(Thread.currentThread(), PROBE); } }
首先会对 Base 值进行 CAS 更新,当 Base 发生竞争时, 会更新数组内的 Cell 。
数组未初始化,Cell 未初始化, Cell 更新失败,即 Cell 也发生竞争时,会调用 Striped64 的 longAccumulate 方法。
Striped64#longAccumulate 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 abstract class Striped64 extends Number { final void longAccumulate (long x, LongBinaryOperator fn, boolean wasUncontended) { int h; if ((h = getProbe()) == 0 ) { ThreadLocalRandom.current(); h = getProbe(); wasUncontended = true ; } boolean collide = false ; for (;;) { Cell[] as; Cell a; int n; long v; if ((as = cells) != null && (n = as.length) > 0 ) { if ((a = as[(n - 1 ) & h]) == null ) { if (cellsBusy == 0 ) { Cell r = new Cell (x); if (cellsBusy == 0 && casCellsBusy()) { boolean created = false ; try { Cell[] rs; int m, j; if ((rs = cells) != null && (m = rs.length) > 0 && rs[j = (m - 1 ) & h] == null ) { rs[j] = r; created = true ; } } finally { cellsBusy = 0 ; } if (created) break ; continue ; } } collide = false ; } else if (!wasUncontended) wasUncontended = true ; else if (a.cas(v = a.value, ((fn == null ) ? v + x : fn.applyAsLong(v, x)))) break ; else if (n >= NCPU || cells != as) collide = false ; else if (!collide) collide = true ; else if (cellsBusy == 0 && casCellsBusy()) { try { if (cells == as) { Cell[] rs = new Cell [n << 1 ]; for (int i = 0 ; i < n; ++i) rs[i] = as[i]; cells = rs; } } finally { cellsBusy = 0 ; } collide = false ; continue ; } h = advanceProbe(h); } else if (cellsBusy == 0 && cells == as && casCellsBusy()) { boolean init = false ; try { if (cells == as) { Cell[] rs = new Cell [2 ]; rs[h & 1 ] = new Cell (x); cells = rs; init = true ; } } finally { cellsBusy = 0 ; } if (init) break ; } else if (casBase(v = base, ((fn == null ) ? v + x : fn.applyAsLong(v, x)))) break ; } } }
longAccumulate 方法一共有三种情况
(as = cells) != null && (n = as.length) > 0 数组不为空且长度大于 0 。
获取索引处的 cell , cell 为空则进行初始化。
cell 不为空,使用 cas 更新, 成功 break; 跳出循环, 失败则还在循环内,会一直尝试。
collide 指是否发生冲突,冲突后会进行重试。
冲突后会尝试获得锁并进行扩容,扩容长度为原来的 2 倍,然后继续重试。
获得锁失败(说明其他线程在扩容)会重新进行计算探针值。
cellsBusy == 0 && cells == as && casCellsBusy() 数组为空,获得乐观锁成功。
直接初始化数组。
初始数组长度为 2 。
casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x))) 获得乐观锁失败。
说明有其他线程在初始化数组,直接 CAS 更新 base 。
LongAdder#sum 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class LongAdder extends Striped64 implements Serializable { public long sum () { Cell[] as = cells; Cell a; long sum = base; if (as != null ) { for (int i = 0 ; i < as.length; ++i) { if ((a = as[i]) != null ) sum += a.value; } } return sum; } }
数组为空,说明没有发生竞争,直接返回 base 。
数组不为空,说明发生竞争,累加 cell 的 value 和 base 的和进行返回。
总结 基本流程
LongAdder 继承了 Striped64,内部维护一个 Cells 数组,相当于多个 Cell 变量, 每个 Cell 里面都有一个初始值为 0 的 long 型变量。
未发生竞争时(Cells 数组未初始化),是对 base 变量进行原子操作。
发生竞争时,每个线程对自己的 Cell 变量的 value 进行原子操作。
如何确定哪个线程操作哪个 cell? 通过 getProbe() 方法获取该线程的探测值,然后和数组长度 n - 1 做 & 操作 (n - 1) & h 。
1 2 3 static final int getProbe () { return UNSAFE.getInt(Thread.currentThread(), PROBE); }
Cells 数组初始化及扩容? 初始化扩容时会判断 cellsBusy, cellsBusy 使用 volatile 修饰,保证线程见可见性,同时使用 CAS 进行更新。 0 表示空闲,1 表示正在初始化或扩容。
初始化时会创建长度为 2 的 Cell 数组。扩容是创建一个长度是原数组长度 2 倍的新数组,并循环赋值。
如果线程访问分配的 Cell 元素有冲突后,会使用 advanceProbe() 方法重新获取探测值,再次进行尝试。
使用场景 在高并发情况下,需要相对高的性能,同时数据准确性要求不高,可以考虑使用 LongAdder。
当要保证线程安全,并允许一定的性能损耗时,并对数据准确性要求较高,优先使用 AtomicLong。