
前言
自从 DocView 发布了简陋的第一版之后,就不断地有小伙伴提建议意见等等,希望扩展各种功能。这不,时隔两周,DocView 又发布了新版本,本次的更新主要涉及到支持 Dubbo,以及支持导出单个文档为 Markdown 文件。来一起看看新功能吧!
支持导出 Markdown 文件
DocView 原版本已经支持复制到剪贴板的功能。
而在新版本中增加了 Export 按钮,可以将单个文档导出为 Markdown 文件。
来一张动图,大家看看效果:
导出的 Markdown 文本内容如下:
支持 Dubbo 接口
之前的版本是不支持 Dubbo 接口的,而现在的版本可以在 Dubbo 接口里面使用。
当然这里并没有校验接口是否为 Dubbo 接口,只是校验了下是否为接口。所以说即使其他接口也是可以生成的。
这块还是需要完善的!
DocView 文档地址
在面板左下角的 help 按钮修改了跳转地址为:http://docview.liuzhihang.com/
只是粗略搭建了一个 DocView 的说明文档网站,小伙伴们可以发现这个网站连 logo 都没有。
其 ...
issue
未读问题
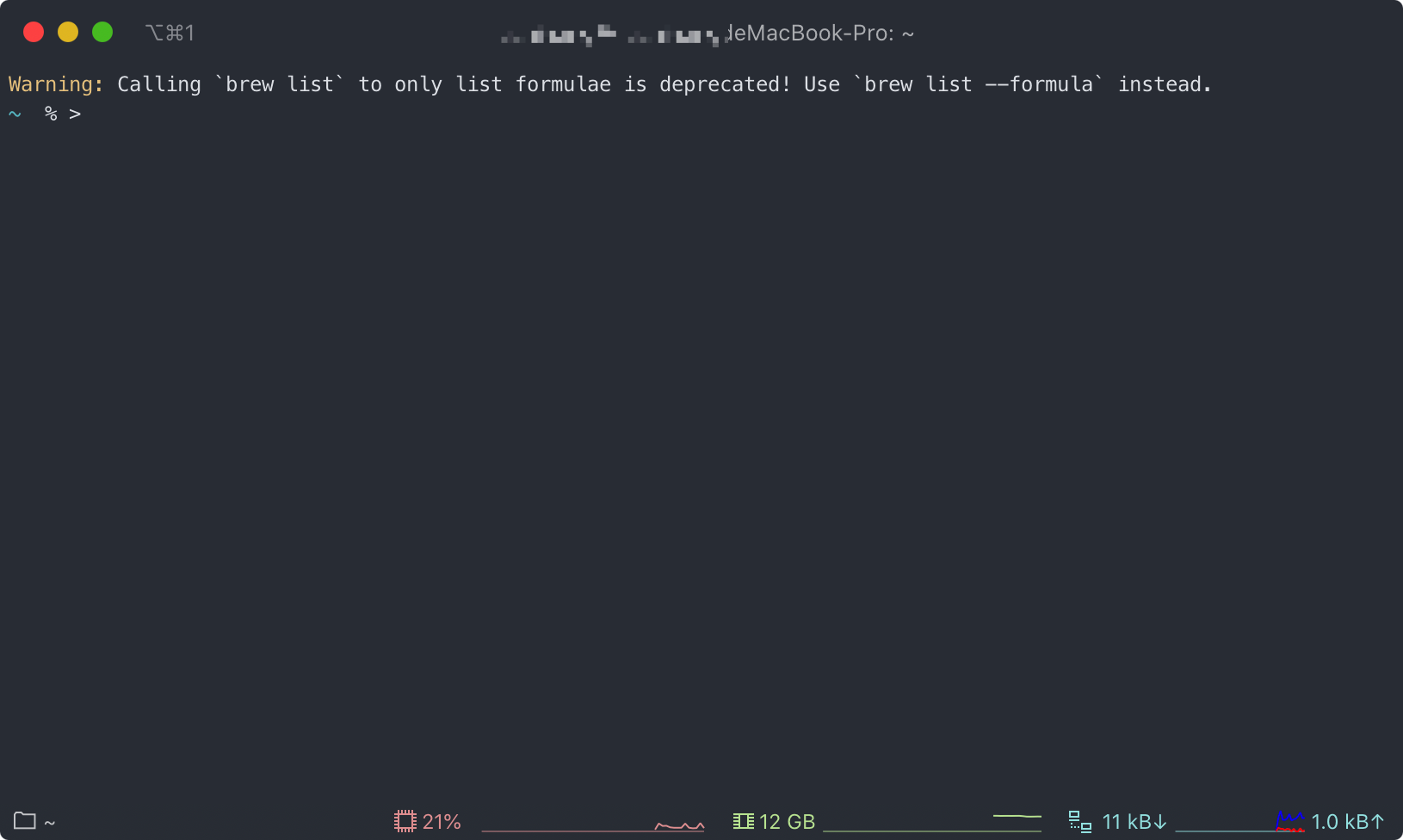
最近终端总是弹出这么一句话,咱也不懂怎么解决。
Google baidu 也查不到问题。
小伙伴帮忙看一下。
每次新打开终端都会有这个 Warning 。
Warning: Calling `brew list` to only list formulae is deprecated! Use `brew list --formula` instead.
最后被逼无奈,在 V 站 发帖求助小伙伴, 结果还真找到了答案
解决方式
最后找到问题所在,是因为按照网上的教程安装的 Coreutils
~/.zshrc 里改一下即可。
补充
写到这里,很多小伙伴应该已经知道问题所在了,可能有的小伙伴还不知道怎么解决:
vim ~/.zshrc
找到使用 brew list 的地方
将 brew list 改为 brew list --formula
如果还不知道怎么弄,那可以用编辑工具打开 .zshrc 文件,然后搜索找到 brew list ,然后替换。

前言
相信大家都遇到一种事务失效场景,那就是 Spring 自调用,就是在 Service 方法内,调用另一个加 @Transactional 注解的方法,发现事务失效,这时候你是怎么解决的呢?
事情回顾
那是一个我忘了天气咋样的下午,突然蹦出一个小红点,嗯~ 挺着急的小红点。
原来是事务失效了!
莫慌!莫慌!
最后小伙伴选择了抽走,是我的工具类不香了么?
当然故事的结果是完美的,问题解决了。
事务
在开发中涉及到同时操作多个表的时候,要保证两个操作要么一起成功,要么一起失败,这时候就需要用到事务。
现在一般使用的都是基于 @Transactional 注解的声明式事务。
而事务使用过程中有以下几个注意事项:
事务只能应用到 public 方法上才会有效;
事务需要从外部调用,Spring 自调用会失效;
建议事务注解 @Transactional 一般添加在实现类上。
当然这几句话不是说我的,人家官方文档可是明确说明的!
这里可是说明了应仅将 @Transactional 注解应用于具有公开可见性的方法。如果对受 protected, private o或 p ...

前言
每次开发完新项目或者新接口功能等,第一件事就是提供接口文档。说到接口文档,当然是用 Markdown 了。各种复制粘贴字段,必填非必填,字段备注,请求返回示例等等。简直是浪费时间哇。所以想到了开发一款插件来解决重复复制文档的问题。下面来看我介绍介绍这款插件。
PS:插件比较简陋,还需要不断迭代。
为什么开发插件
每次在对外提供接口时都要写文档,各种麻烦,并且文档耗费了很大一部分时间。也使用了一些文档工具,在线写作工具,最终还是比较喜欢自己手写文档。
使用过的生成工具
Swagger : 添加依赖,配置类及描述信息,然后在方法及实体上添加注解,启动项目便可以通过访问 xxxx/swagger-ui.html 查看接口文档;
API Doc :添加配置文件及注释,安装 npm 并通过执行命令生成文档;
SmartDoc :添加依赖及注释后执行测试类生成文档;
API2DOC :添加依赖,开启注解,通过注解配置生成文档。
上面四种方法,无疑都需要添加依赖,使用注解等方式,可以说有一定的代码侵入性。
使用过的接口文档工具
ShowDoc :曾经一段时间很喜欢用这个, Mark ...
前言
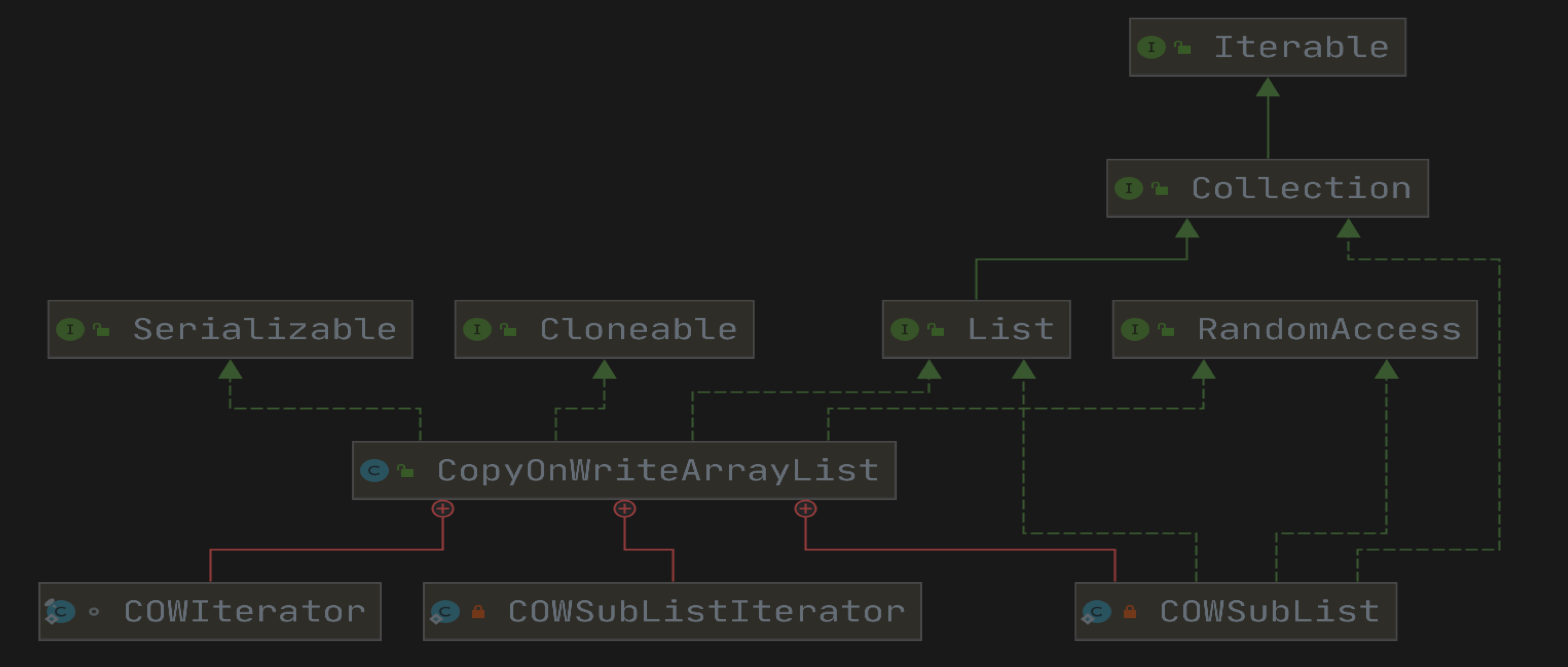
JUC 下面还有一个系列的类,都是 CopyOnWriteXXX ,意思是写时复制,这个究竟是怎么回事?那就以 CopyOnWriteArrayList 为切入点,一起了解写时复制是怎么回事?
介绍
ArrayList 的一个线程安全的变体,其中所有可变操作(add、set 等等)都是通过对底层数组进行一次新的复制来实现的。
像名字一样,每次进行操作的时候,都会进行一次复制,当然会有很大的性能消耗,但是在某些使用场景下,又会提高性能。具体是怎么操作的,那就一步一步阅读源码,然后再做总结归纳。
基本使用
1234567891011121314151617181920212223public class CopyOnWriteArrayListTest { public static void main(String[] args) { CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>(); // 添加元素 li ...
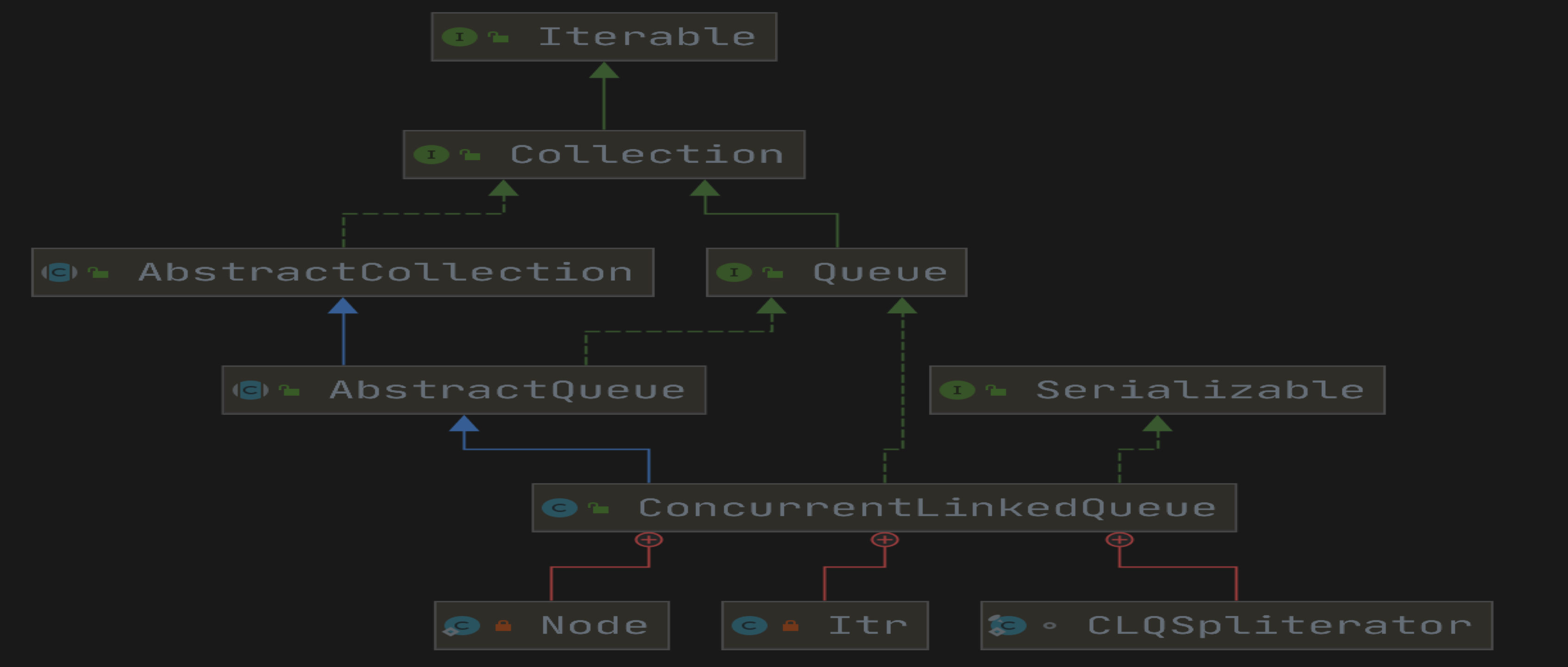
前言
JUC 下面的相关源码继续往下阅读,这就看到了非阻塞的无界线程安全队列 —— ConcurrentLinkedQueue,来一起看看吧。
介绍
基于链接节点的无界线程安全队列,对元素FIFO(先进先出)进行排序。 队列的头部是队列中最长时间的元素,队列的尾部是队列中最短时间的元素。 在队列的尾部插入新元素,队列检索操作获取队列头部的元素。
当许多线程共享对公共集合的访问 ConcurrentLinkedQueue 是一个合适的选择。 与大多数其他并发集合实现一样,此类不允许使用null元素。
基本使用
123456789101112131415161718public class ConcurrentLinkedQueueTest { public static void main(String[] args) { ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue<String>(); // 将指定元素插入此队列的尾部。 ...

前言
部署测试,部署预发布,一切测试就绪,上生产。
发布生产
闪退
What???
马上回滚
开始排查
后端一模一样的代码,不是 APP 端的问题吧。可 APP 端没有发版啊。
…… 一番排查
原来是 APP 端打包,测试和预发布包 Header 传的都是 Authorization ,生产传的是 authorization 。就是大小写问题,那赶紧改。
背景
首页接口只有登录才可以进入,因为首页要展示获取用户账户的一些信息。这里使用的是统一拦截,从 Header 中获取 token 后,使用 token 获取用户信息。
而现在要改为用户未登录也可以查看首页信息中的宣传文案等等,只不过账户信息不显示。
原流程
整个过程代码在 ThreadLocal底层原理 里面有所介绍。这里省略一部分代码。
123456789101112131415161718192021222324252627282930313233343536373839404142@Componentpublic class TokenInterceptor implements HandlerInterceptor ...
前言
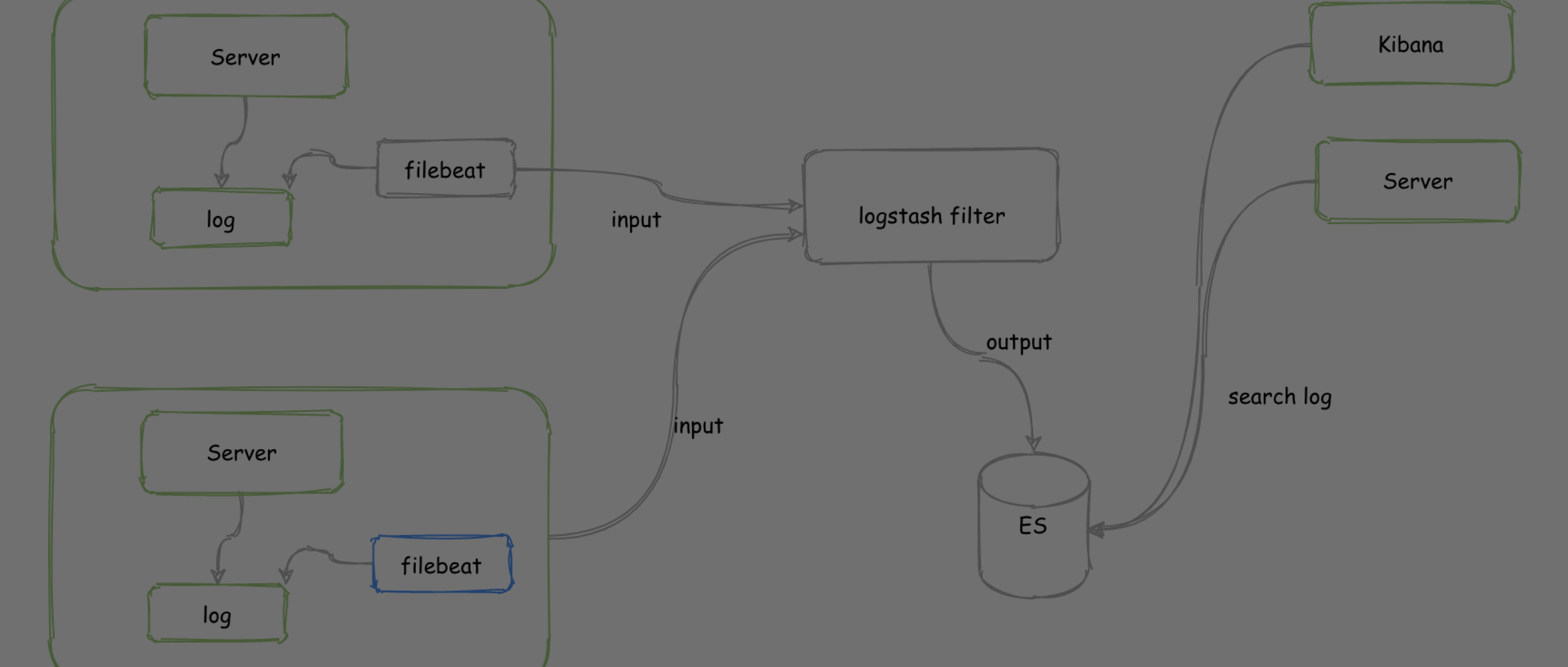
新项目查日志太麻烦,多台机器之间查来查去,还不知道是不是同一个请求的。打印日志时使用 MDC 在日志上添加一个 traceId,那这个 traceId 如何跨系统传递呢?
背景
同样是新项目开发的笔记,因为使用的是分布式架构,涉及到各个系统之间的交互
这时候就会遇到一个很常见的问题:
单个系统是集群部署,日志分布在多台服务器上;
多个系统的日志在多台机器,但是一次请求,查日志更是难上加难。
解决方案
使用 SkyWalking traceid 进行链路追踪;
使用 Elastic APM 的 trace.id 进行链路追踪;
自己生成 traceId 并 put 到 MDC 里面。
MDC
MDC(Mapped Diagnostic Context)是一个映射,用于存储运行上下文的特定线程的上下文数据。因此,如果使用log4j进行日志记录,则每个线程都可以拥有自己的MDC,该MDC对整个线程是全局的。属于该线程的任何代码都可以轻松访问线程的MDC中存在的值。
如何使用 MDC
在 log4j2-spring.xml 的日志格式中添加 %X{trace ...

又要开始新项目了,一顿操作猛如虎,梳理流程加画图。这不,开始对流程及表结构了。
我:吧啦吧啦吧啦 ……
老大:这个建表为啥还设置个自增 id ?直接用流水号(用户号/产品号)当主键不就行了?
我:这个是 DBA 规定的,创建表 id、create_time、update_time 这三个字段都要有。《Java 开发规范》也是这么规定的。
小伙伴:(附和)是的,规定的是这样的!
老大:流水号在你这是唯一索引吧?设置成主键,这样就不用 id 了,还减少一次回表查询?
我:…… (说的好像很有道理,咱也不敢说话。)
老大:既然他们规定了,那你回去查一下为什么要设计个自增 id ?
我:掏出小本本(回去查资料~)。
建表规约
在工作中,创建表的时候,DBA 也会审核一下建表 SQL,检查是否符合规范以及常用字段是否设置索引。
12345678CREATE TABLE `xxxx` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键', `create_time` datetime(3) NOT NUL ...
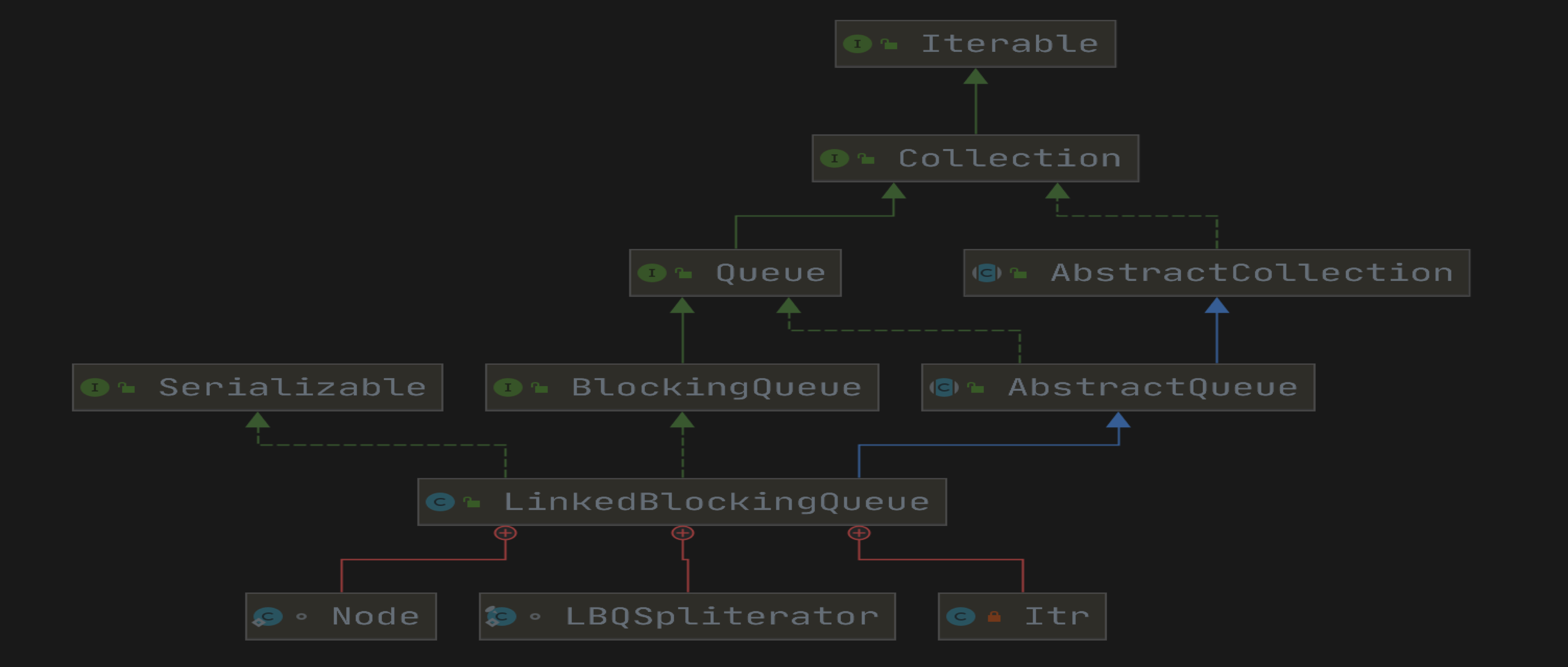
前言
上一节看了基于数据的有界阻塞队列 ArrayBlockingQueue 的源码,通过阅读源码了解到在 ArrayBlockingQueue 中入队列和出队列操作都是用了 ReentrantLock 来保证线程安全。下面咱们看另一种有界阻塞队列:LinkedBlockingQueue。
介绍
一个基于链接节点的,可选绑定的 BlockingQueue 阻塞队列。
对元素 FIFO(先进先出)进行排序。队列的头部是已在队列中停留最长时间的元素。队列的尾部是最短时间出现在队列中的元素。将新元素插入队列的尾部,并检索队列操作获取队列开头的元素。
基于连表的队列通常具有比基于数组的队列有更高的吞吐量,但是大多数并发应用程序中的可预测性较差。
基本使用
1234567891011121314151617181920212223242526public class LinkedBlockingQueueTest { private static final LinkedBlockingQueue<String> QUEUE = new LinkedBlocki ...
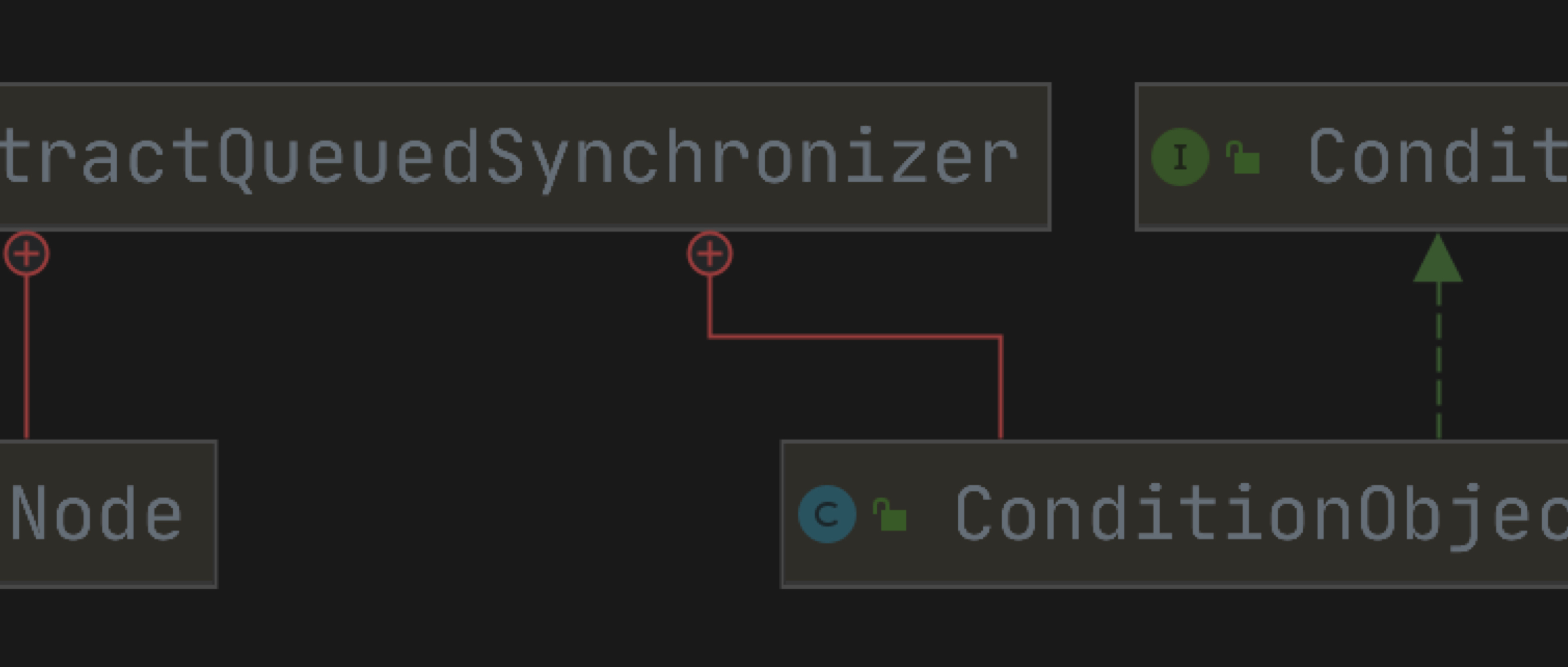
前言
在介绍 AQS 时,其中有一个内部类叫做 ConditionObject,当时并没有进行介绍,并且在后续阅读源码时,会发现很多地方用到了 Condition ,这时就会很诧异,这个 Condition 到底有什么作用?那今天就通过阅读 Condition 源码,从而弄清楚 Condition 到底是做什么的?当然阅读这篇文章的时候希望你已经阅读了 AQS、ReentrantLock 以及 LockSupport 的相关文章或者有一定的了解(当然小伙伴也可以直接跳到文末看总结)。
介绍
Object 的监视器方法:wait、notify、notifyAll 应该都不陌生,在多线程使用场景下,必须先使用 synchronized 获取到锁,然后才可以调用 Object 的 wait、notify。
Condition 的使用,相当于用 Lock 替换了 synchronized,然后用 Condition 替换 Object 的监视器方法。
Conditions(也称为条件队列或条件变量)为一种线程提供了一种暂停执行(等待),直到另一线程通知被阻塞的线程,某些状态条件现在可能为 ...
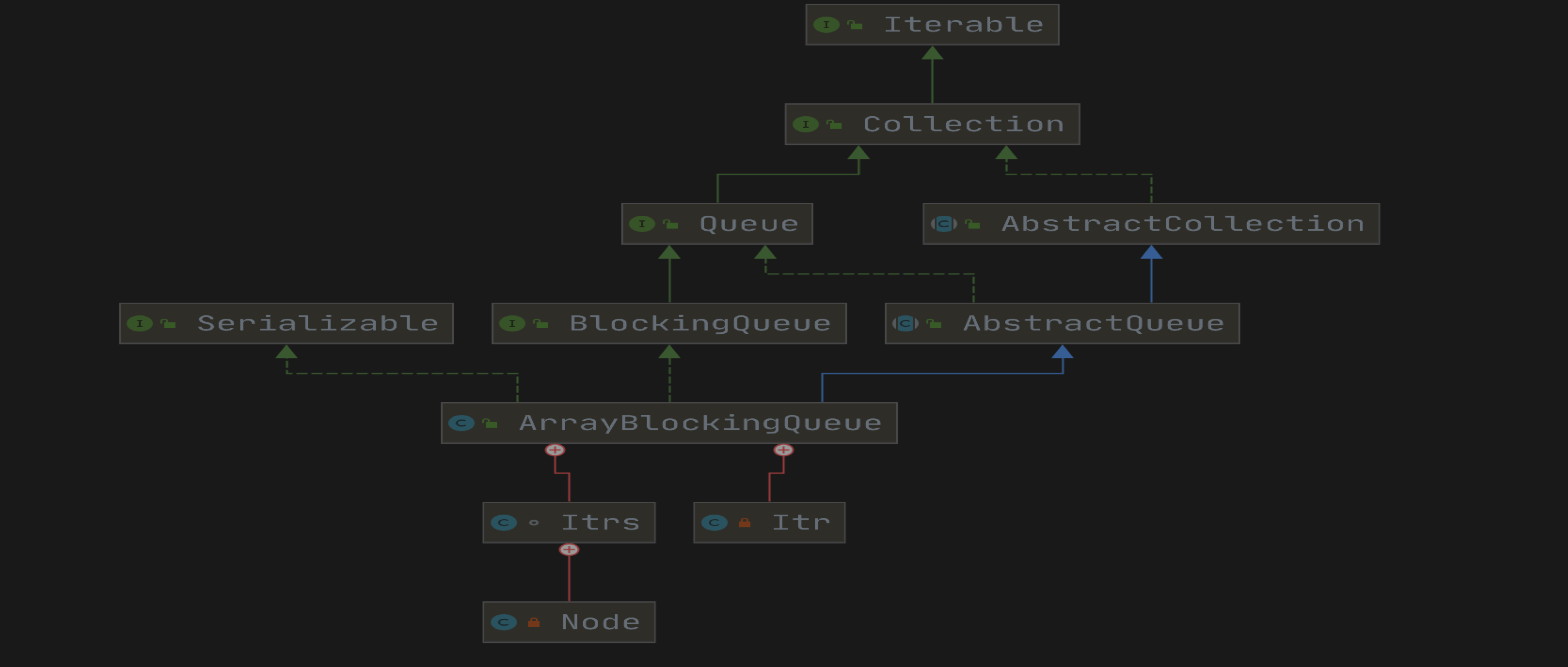
前言
在阅读完和 AQS 相关的锁以及同步辅助器之后,来一起阅读 JUC 下的和队列相关的源码。先从第一个开始:ArrayBlockingQueue。
介绍
由数组支持的有界BlockingQueue阻塞队列。
这个队列的命令元素FIFO(先入先出)。 队列的头是元素一直在队列中时间最长。 队列的尾部是该元素已经在队列中的时间最短。 新元素插入到队列的尾部,并且队列检索操作获取在队列的头部元素。
这是一个典型的“有界缓冲区”,在其中一个固定大小的数组保持由生产者插入并受到消费者的提取的元素。 一旦创建,容量不能改变。 试图put 一个元素到一个满的队列将导致操作阻塞; 试图 take 从空队列一个元素将类似地阻塞。
此类支持订购等待生产者和消费者线程可选的公平政策。 默认情况下,这个顺序不能保证。 然而,队列公平设置为构建 true 保证线程以FIFO的顺序进行访问。 公平性通常会降低吞吐量,但减少了可变性和避免饥饿。
基本使用
1234567891011121314151617181920212223242526272829303132333435363738394041424 ...




