工作笔记链路追踪工作笔记链路追踪几行代码轻松实现跨系统传递 traceId,再也不用担心对不上日志了!
liuzhihang
前言
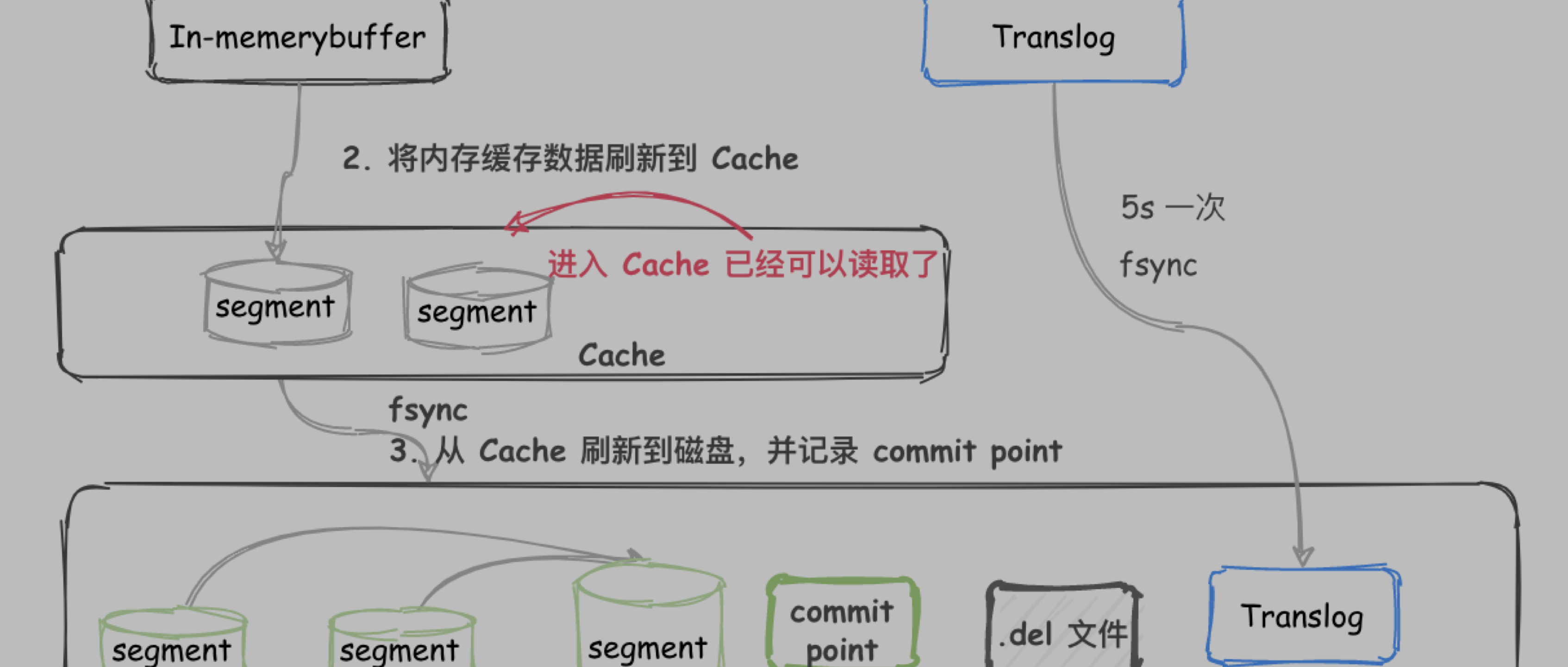
新项目查日志太麻烦,多台机器之间查来查去,还不知道是不是同一个请求的。打印日志时使用 MDC 在日志上添加一个 traceId,那这个 traceId 如何跨系统传递呢?
背景
同样是新项目开发的笔记,因为使用的是分布式架构,涉及到各个系统之间的交互

这时候就会遇到一个很常见的问题:
- 单个系统是集群部署,日志分布在多台服务器上;
- 多个系统的日志在多台机器,但是一次请求,查日志更是难上加难。
解决方案
- 使用 SkyWalking traceid 进行链路追踪;
- 使用 Elastic APM 的 trace.id 进行链路追踪;
- 自己生成 traceId 并 put 到 MDC 里面。
MDC
MDC(Mapped Diagnostic Context)是一个映射,用于存储运行上下文的特定线程的上下文数据。因此,如果使用log4j进行日志记录,则每个线程都可以拥有自己的MDC,该MDC对整个线程是全局的。属于该线程的任何代码都可以轻松访问线程的MDC中存在的值。
如何使用 MDC
- 在 log4j2-spring.xml 的日志格式中添加
%X{traceId} 配置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| <Property name="LOG_PATTERN">
[%d{yyyy-MM-dd HH:mm:ss.SSS}]-[%t]-[%X{traceId}]-[%-5level]-[%c{36}:%L]-[%m]%n
</Property>
<Property name="LOG_PATTERN_ERROR">
[%d{yyyy-MM-dd HH:mm:ss.SSS}]-[%t]-[%X{traceId}]-[%-5level]-[%l:%M]-[%m]%n
</Property>
<Console name="Console" target="SYSTEM_OUT" follow="true">
<PatternLayout charset="UTF-8" pattern="${LOG_PATTERN}"/>
</Console>
|
- 新增拦截器
拦截所有请求,从 header 中获取 traceId 然后放到 MDC 中,如果没有获取到,则直接用 UUID 生成一个。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| @Slf4j
@Component
public class LogInterceptor implements HandlerInterceptor {
private static final String TRACE_ID = "traceId";
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception arg3) throws Exception {
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView arg3) throws Exception {
}
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String traceId = request.getHeader(TRACE_ID);
if (StringUtils.isEmpty(traceId)) {
MDC.put(TRACE_ID, UUID.randomUUID().toString());
} else {
MDC.put(TRACE_ID, traceId);
}
return true;
}
}
|
- 配置拦截器
1
2
3
4
5
6
7
8
9
10
11
| @Configuration
public class WebConfig implements WebMvcConfigurer {
@Resource
private LogInterceptor logInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(logInterceptor)
.addPathPatterns("/**");
}
}
|
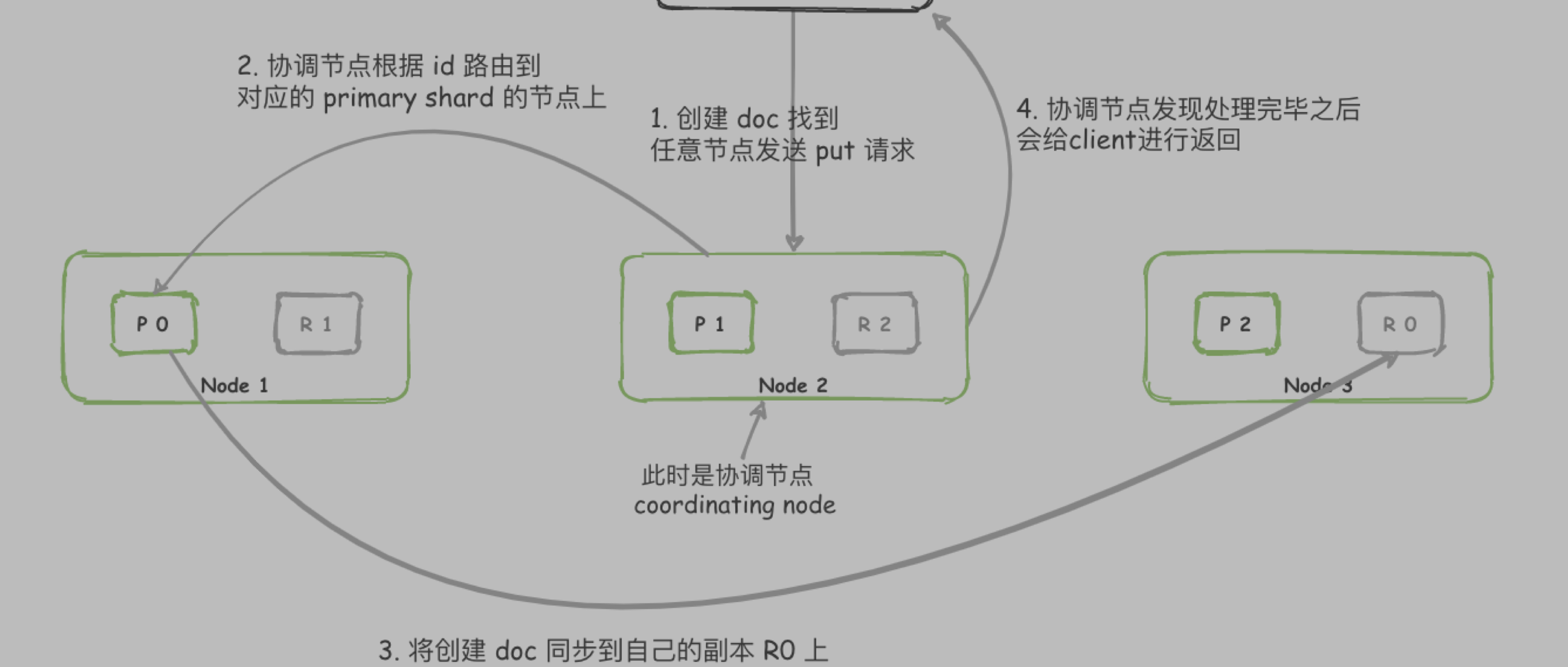
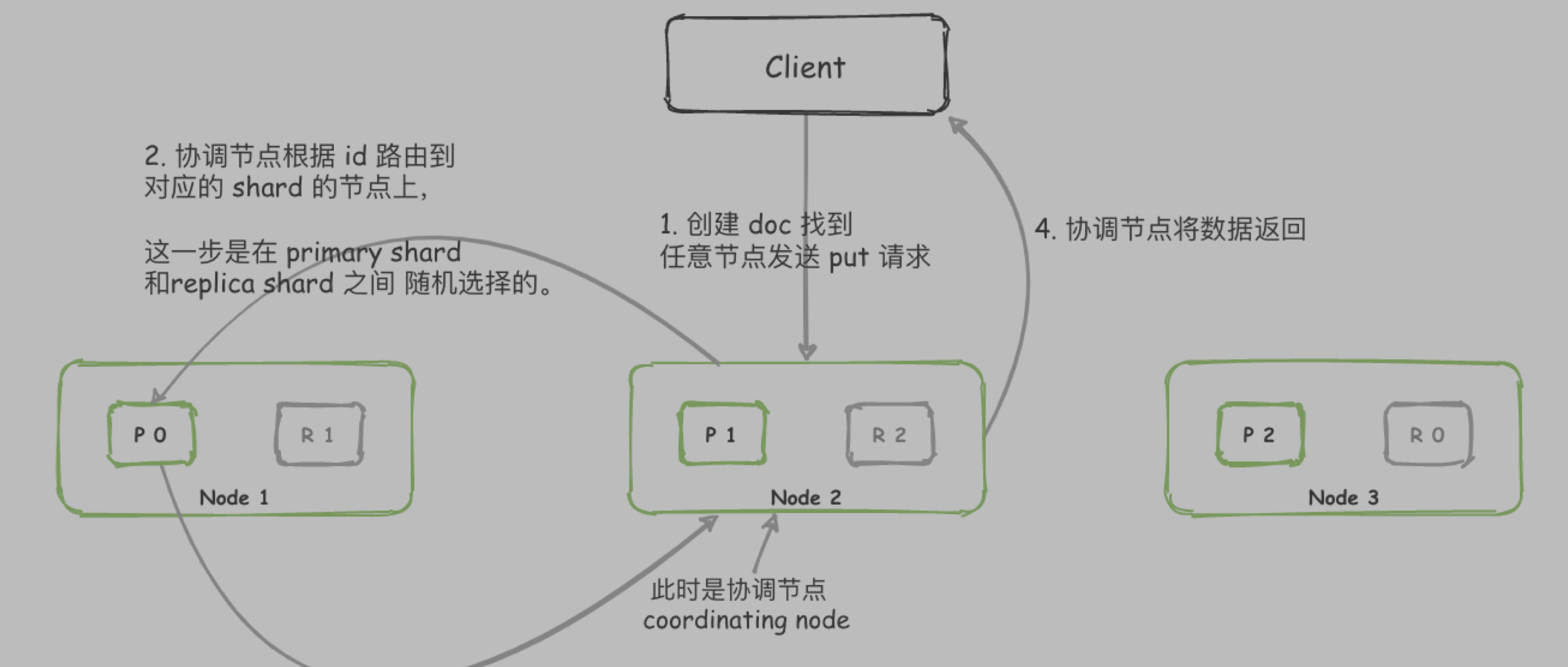
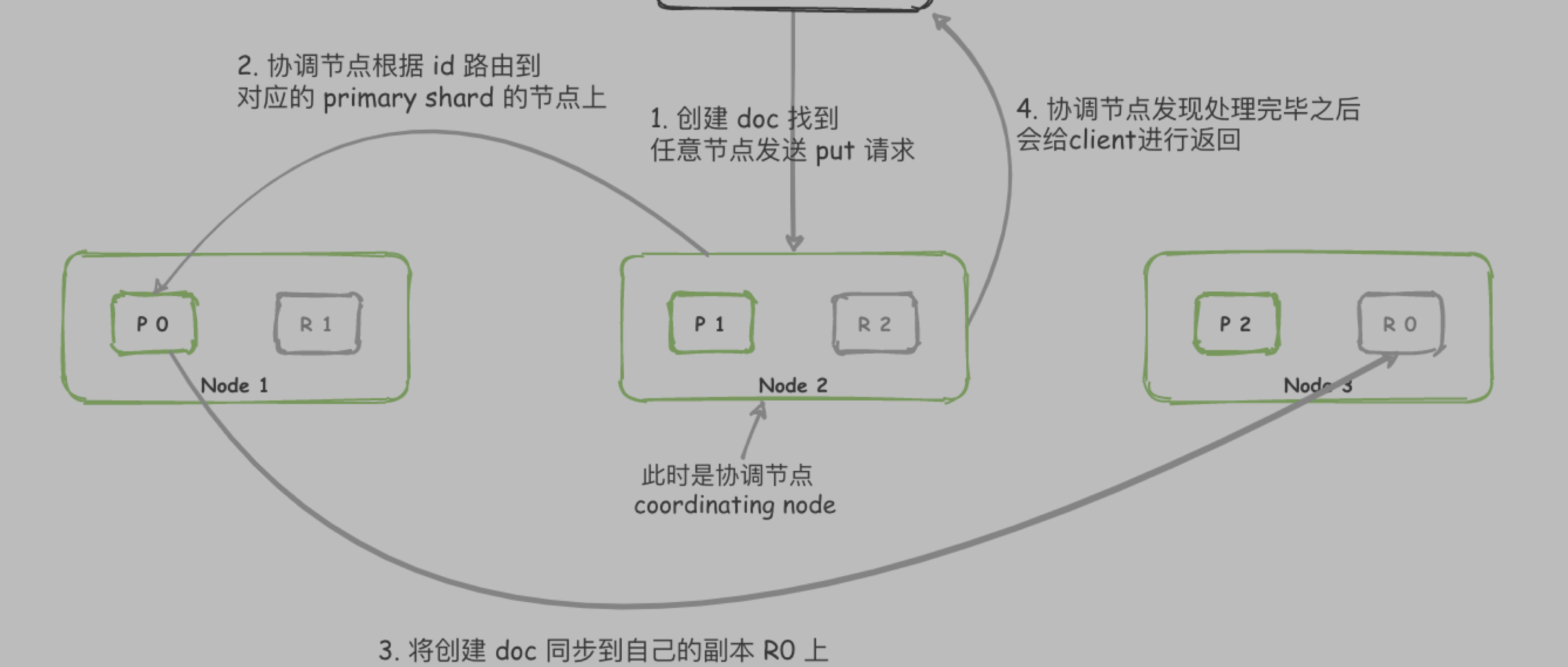
跨服务之间如何传递 traceId
因为这边使用的是 FeignClient 进行服务之间的调用,只需要新增请求拦截器即可
1
2
3
4
5
6
7
8
9
10
11
12
| @Configuration
public class FeignInterceptor implements RequestInterceptor {
private static final String TRACE_ID = "traceId";
@Override
public void apply(RequestTemplate requestTemplate) {
requestTemplate.header(TRACE_ID, MDC.get(TRACE_ID));
}
}
|
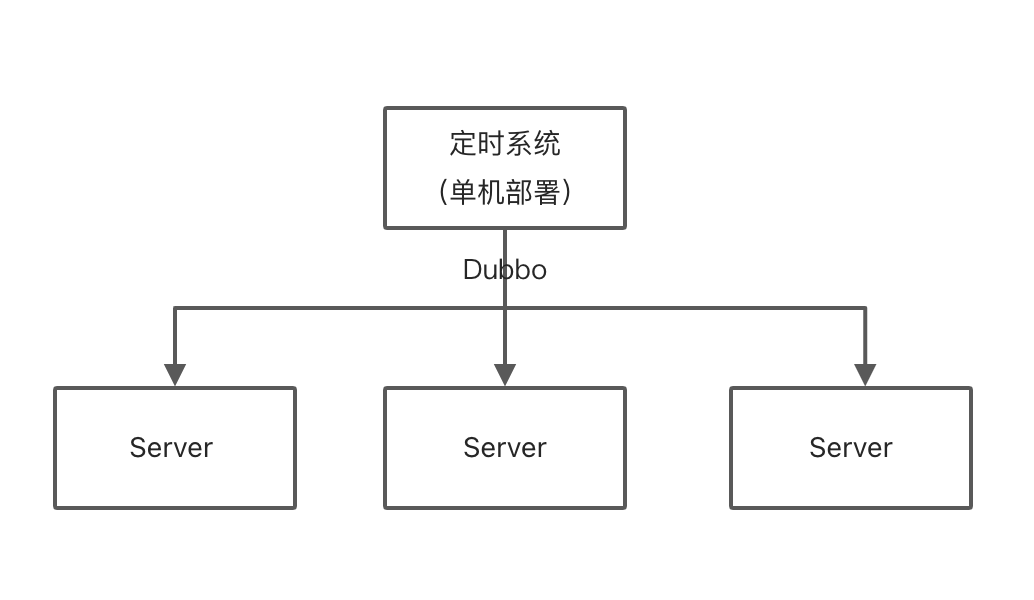
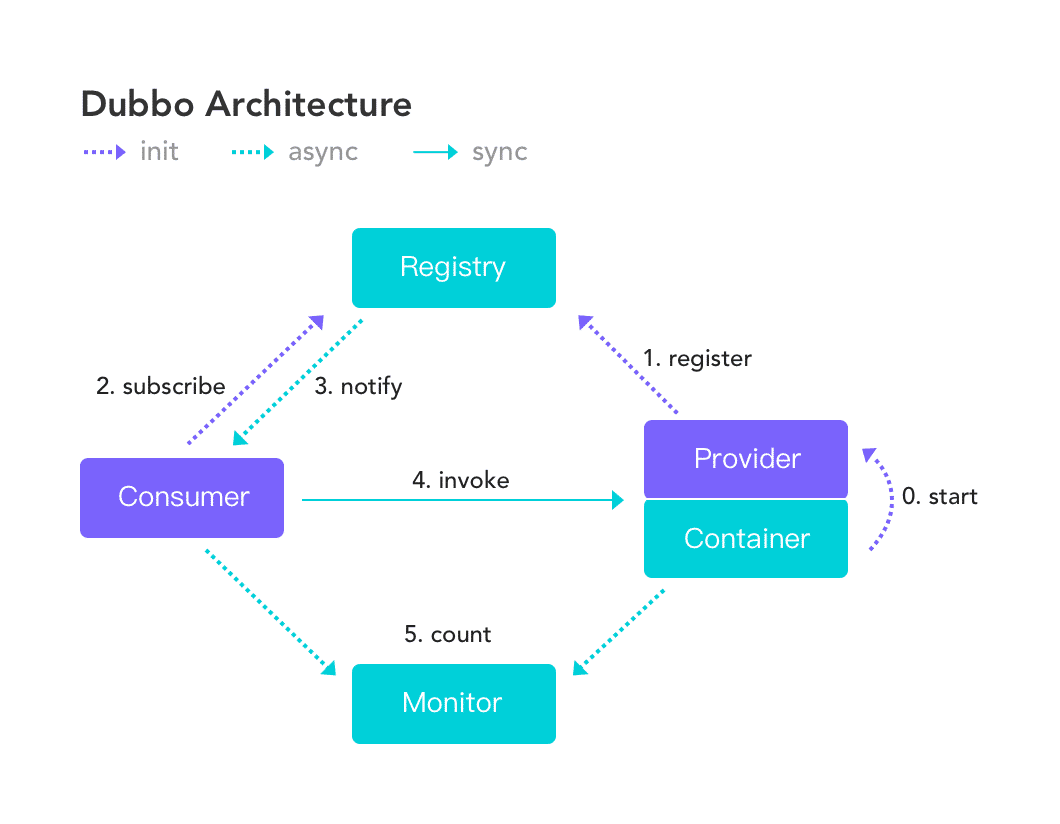
如果是 Dubbo 可以通过扩展 Filter 的方式传递 traceId
- 编写 filter
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| @Activate(group = {"provider", "consumer"})
public class TraceIdFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
RpcContext rpcContext = RpcContext.getContext();
String traceId;
if (rpcContext.isConsumerSide()) {
traceId = MDC.get("traceId");
if (traceId == null) {
traceId = UUID.randomUUID().toString();
}
rpcContext.setAttachment("traceId", traceId);
}
if (rpcContext.isProviderSide()) {
traceId = rpcContext.getAttachment("traceId");
MDC.put("traceId", traceId);
}
return invoker.invoke(invocation);
}
}
|
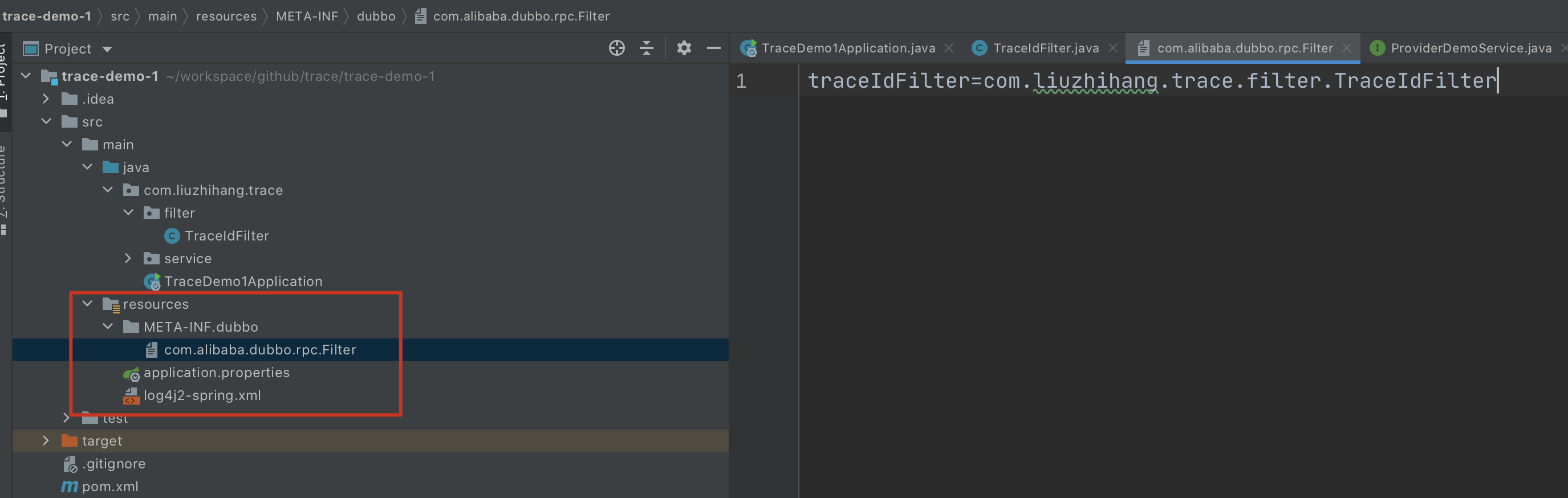
- 指定 filter
1
2
3
4
5
6
7
8
9
10
| src
|-main
|-java
|-com
|-xxx
|-XxxFilter.java (实现Filter接口)
|-resources
|-META-INF
|-dubbo
|-org.apache.dubbo.rpc.Filter (纯文本文件,内容为:xxx=com.xxx.XxxFilter)
|
截图如下:
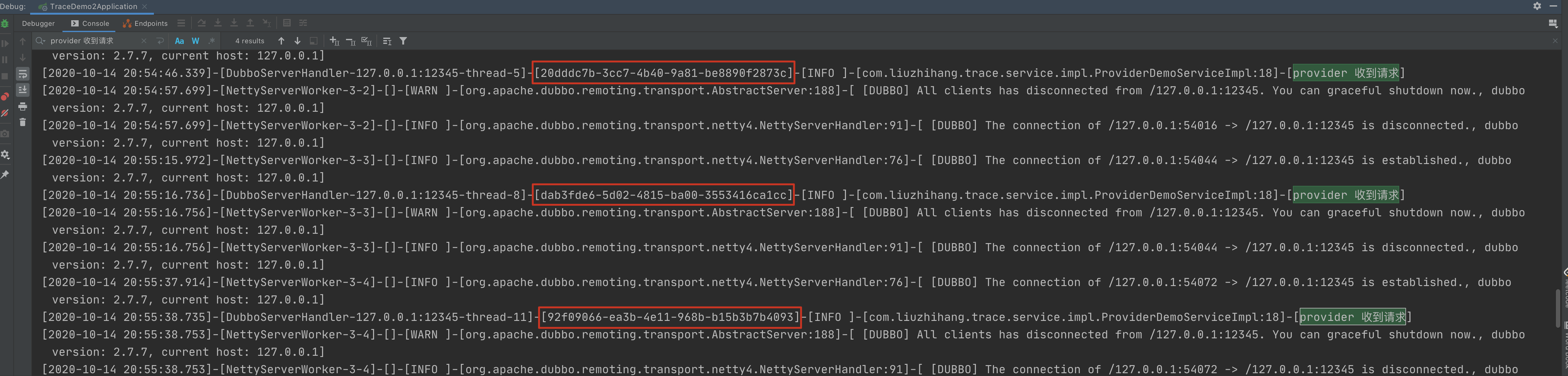
测试结果如下:
dubbo filter 相关源码地址在文末
也可以关注公众号,发送 traceid 获取
其他方式
当然如果小伙伴们有使用 SkyWalking 或者 Elastic APM 也可以通过以下方式进行注入:
- SkyWalking
1
2
3
4
5
| <dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-log4j-2.x</artifactId>
<version>{project.release.version}</version>
</dependency
|
然后将 [%traceId] 配置在 log4j2.xml 文件的 pattern 中即可
-
Elastic APM
- 在启动时指定 enable_log_correlation 为 true
- 将
%X{trace.id} 配置在 log4j2.xml 文件的 pattern 中
扩展
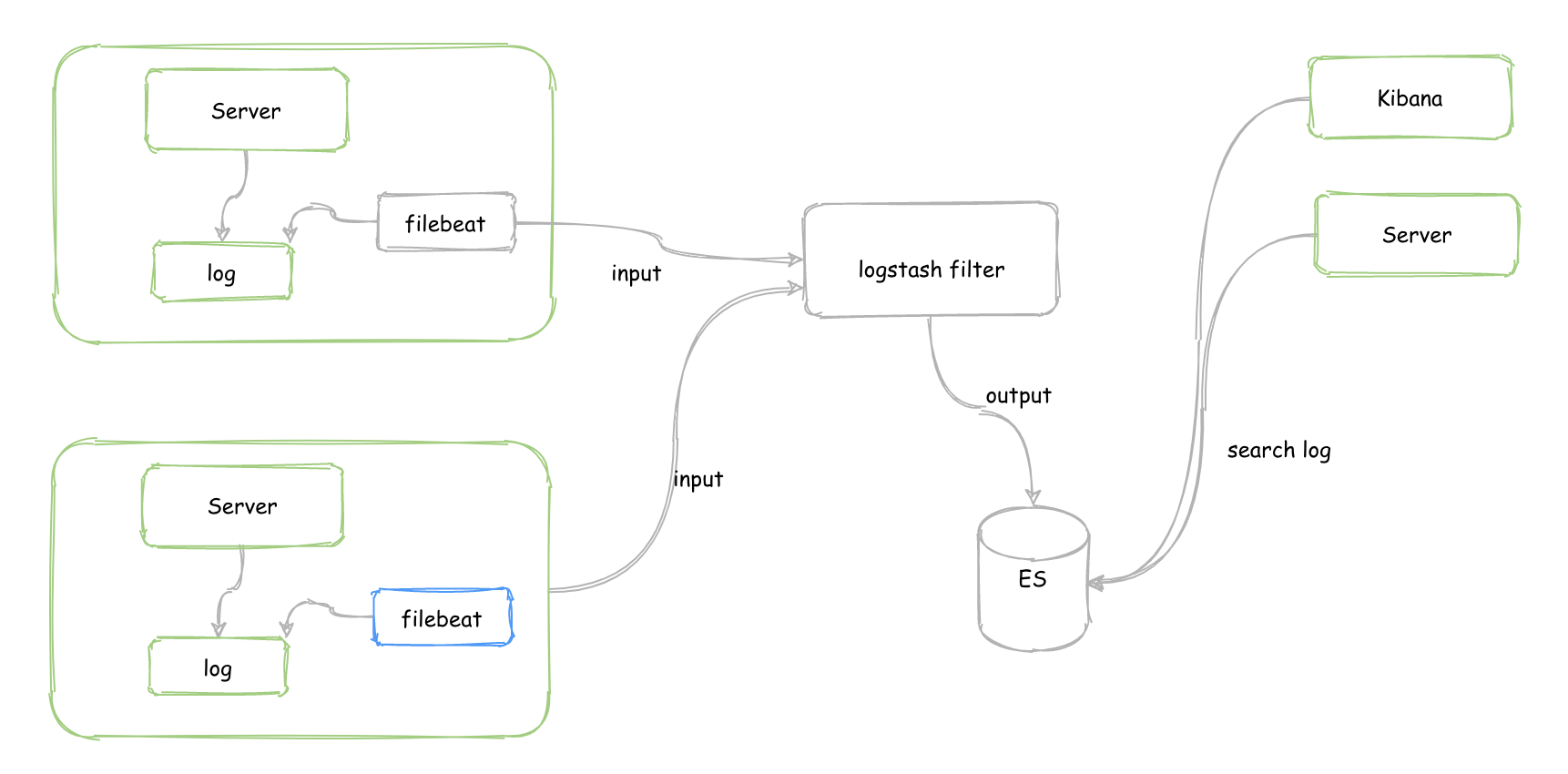
统一日志采集
虽然有了 traceId 可以进行全链路追踪查询日志,但是毕竟也是在多台服务器上,为了提高查询效率,可以考虑将日志汇总到一起。
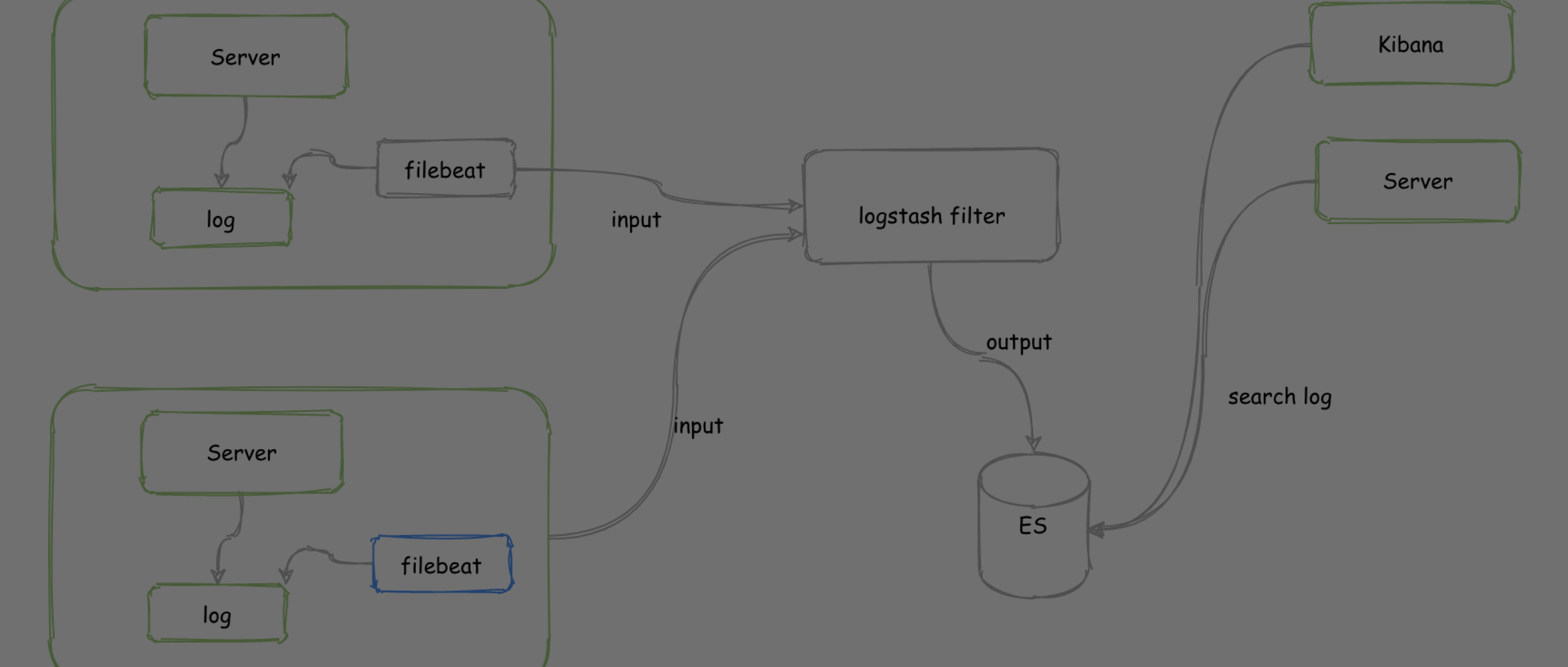
常用的使用方法就是基于 ELK 的日志系统:
- 使用 filebeat 采集日志报送到 logstash
- logstash 进行分词过滤等处理,输出到 Elasticsearch
- 使用 Kinbana 或者自己开发的可视化工具从 Elasticsearch 查询日志
结束语
本文主要记录近期开发过程中的遇到的一点问题,希望对小伙伴也有所帮助。不足之处,欢迎指正。如果小伙伴有其他的建议或者观点欢迎留言讨论,共同进步。
相关资料
- Log4j 2 API:https://logging.apache.org/log4j/2.x/manual/thread-context.html
- SkyWalking:https://github.com/apache/skywalking/tree/master/docs/en/setup/service-agent/java-agent
- Elastic APM:https://www.elastic.co/guide/en/apm/agent/java/current/log-correlation.html
- Dubbo filter:http://dubbo.apache.org/zh-cn/docs/dev/impls/filter.html
- 本文 Dubbo filter demo:https://github.com/liuzhihang/trace