【Elasticsearch 技术分享】—— ES 常用名词及结构
AI-摘要
DeepSeek GPT
AI初始化中...
介绍自己 🙈
生成本文简介 👋
推荐相关文章 📖
前往主页 🏠
前往爱发电购买
【Elasticsearch 技术分享】—— ES 常用名词及结构
liuzhihang前言
看完什么是 Elasticsearch 以及了解到了倒排索引的概念,下面就熟悉下 ES 中常用的一些名词。
常用术语
| 名词 | 解释 |
|---|---|
| cluster | 一个或者多个 node 指定相同的 cluster name,则它们会组成集群,并且自动选举 master,以及在故障时自动选举。 |
| node | 节点是属于集群的Elasticsearch的运行实例 。在启动时,节点将使用单播来发现具有相同集群名称的现有集群,并将尝试加入该集群。 |
| index | 类似关系数据库的表,映射一个或者多个主分片,同时拥有零个或多个副本分片。 |
| index alias | 索引别名是用于引用一个或多个现有索引的辅助名称。大多数Elasticsearch API接受索引别名代替索引名称。 |
| mapping | 每个 index 都有一个 mapping ,定义一个 type 以及许多索引范围的设置。mapping 可以明确定义,也可以在为文档建立索引后自动生成。 |
| shard | 分片是单个Lucene实例。最小的工作单位,由Elasticsearch自动管理。索引是指向主分片和副本分片的逻辑命名空间。 |
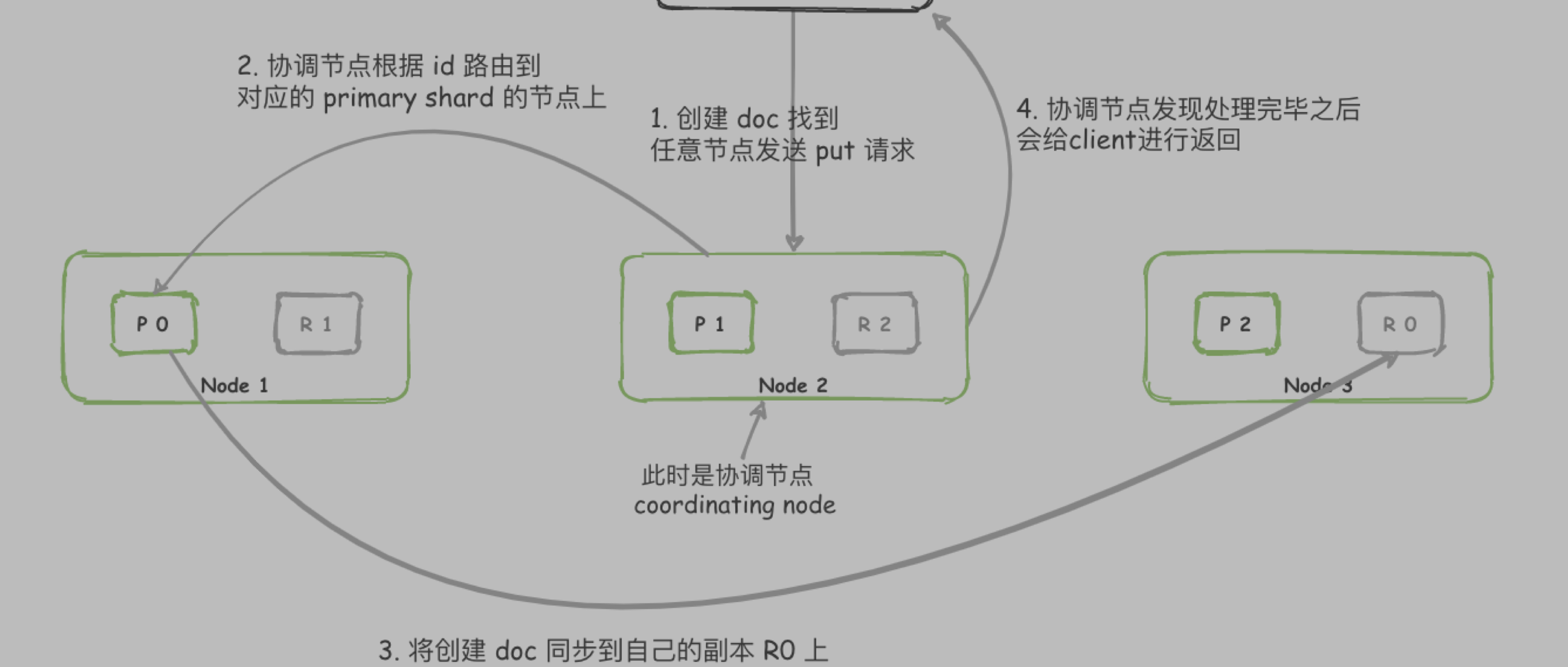
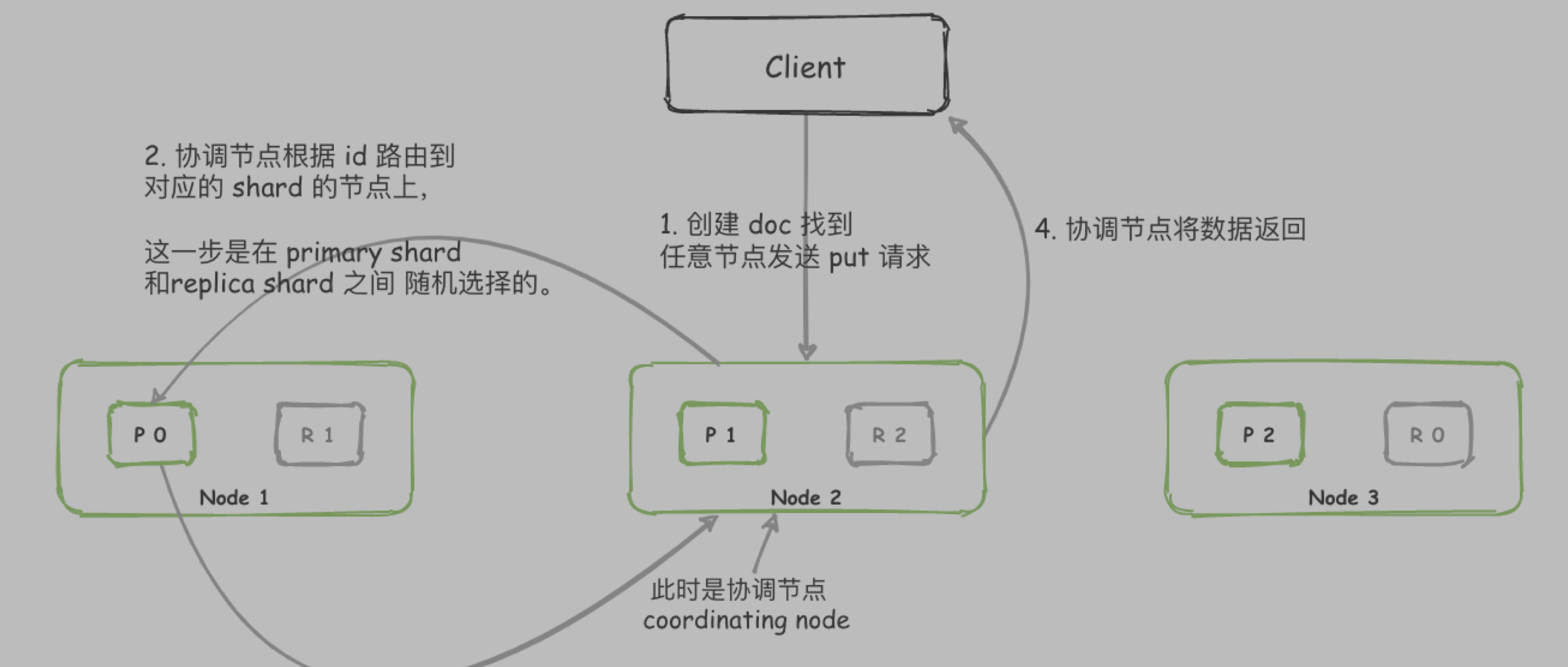
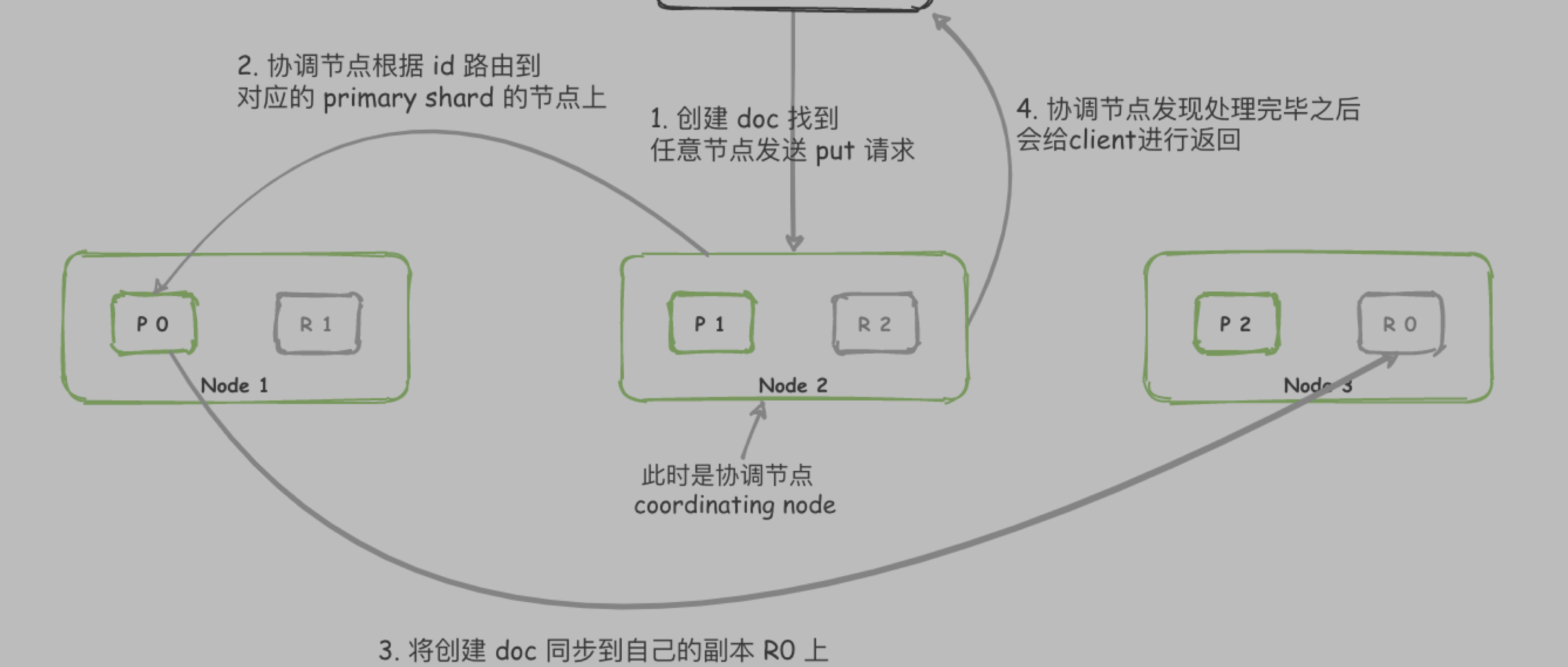
| primary shard | 每个文档都存储在一个主分片中。当您为文档建立索引时,将首先在主 shard 上建立索引,然后在主 shard 的所有副本上建立索引。默认情况下,索引具有一个主分片。您可以指定更多的主要分片来扩展 索引可以处理的文档数量。创建索引后,您将无法更改索引中的主要分片数量。但是,可以使用split API将索引拆分为新索引 。 |
| replica shard | 每个主分片可以具有零个或多个副本。副本是 primary shard 的副本。 |
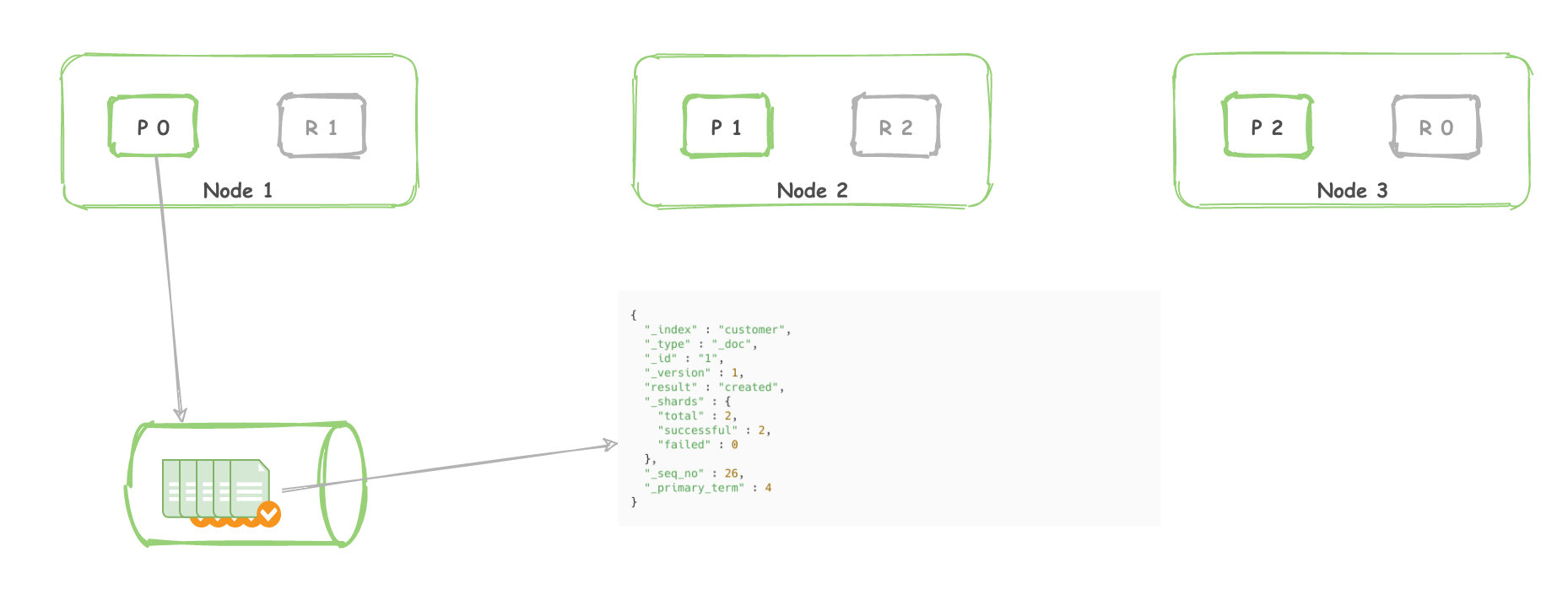
| document | document 是存储在 Elasticsearch 中的 JSON 文档。每个 document 都存储在索引中,并且有 type 和 id。被索引的 JSON 文档 将存储在 _source 字段中,该字段在获取或搜索文档时默认返回。 |
| id | 每个 document 都有不同的 id,没有指定的话,会自动生成。 |
| field | 一个 document 包含字段或键值对的列表。字段类似于关系数据库中表中的列。 |
| source field | 默认情况下,索引的JSON文档存储在 _source 字段中,并且将由所有 get 和 search 请求返回。这样,可以直接从搜索结果中访问原始对象,而无需执行第二步来从 ID 中检索对象。 |
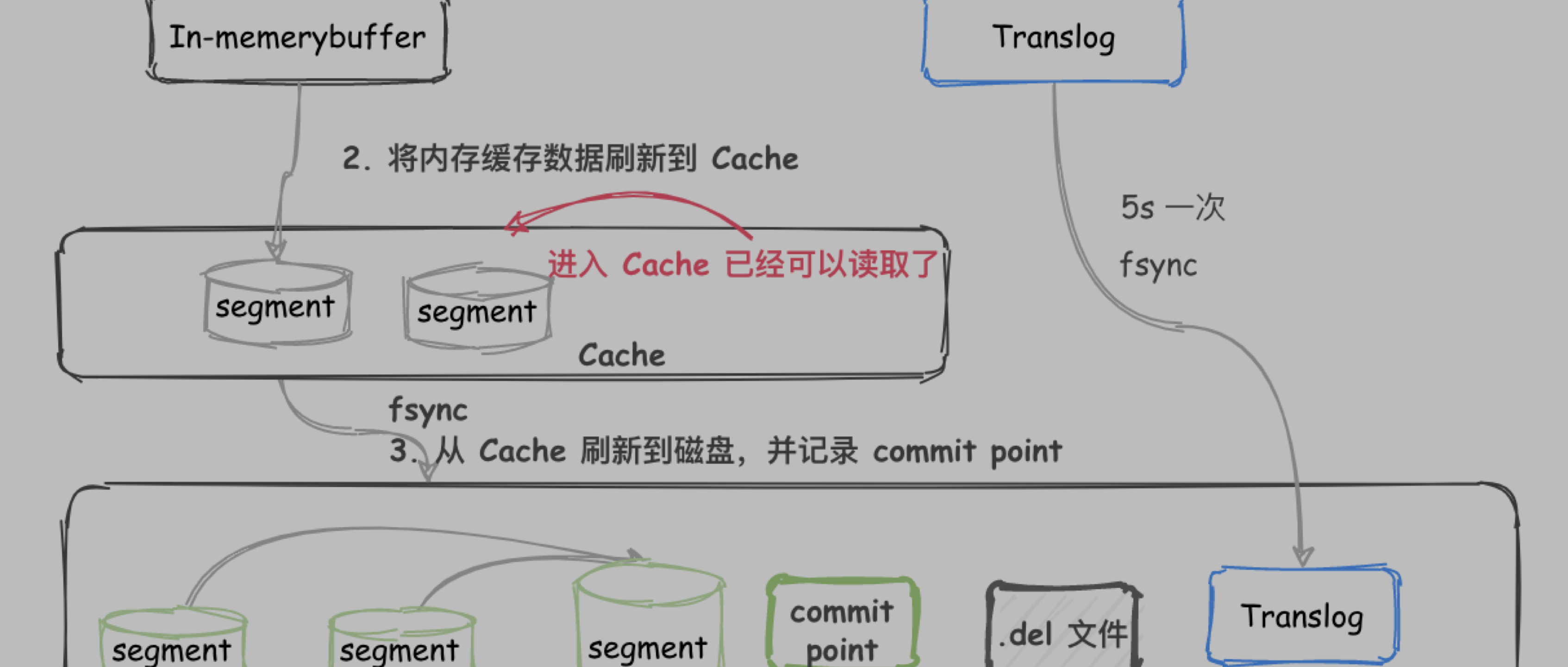
画图出来就是下面这个样子
replica shard 有什么用?
-
增加故障转移:如果主副本发生故障,副本副本可以提升为主副本
-
提高性能:获取和搜索请求可以由主或副本分片处理。
默认情况下,每个主分片都有一个副本,但是可以在现有索引上动态更改副本的数量。副本分片永远不会与其主分片在同一节点上启动。
除了定义索引应具有的主分片和副本分片的数量外,您无需直接引用分片。相反,您的代码应仅处理索引。
Elasticsearch 在 集群中的所有节点之间分配分片,并且在节点发生故障或添加新节点的情况下,可以自动将分片从一个节点移动到另一个节点。
分片 默认是 5个,副本默认为 1个。
总结
这篇文章简单介绍了 ES 的常用名词,因为只有了解到这些名词,在小伙伴讨论 ES 的时候,才不会一脸懵逼。

喜欢这篇文章的人也看了


评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果