【Elasticsearch 技术分享】—— Elasticsearch ?倒排索引?这都是什么?

AI-摘要
DeepSeek GPT
AI初始化中...
介绍自己 🙈
生成本文简介 👋
推荐相关文章 📖
前往主页 🏠
前往爱发电购买
【Elasticsearch 技术分享】—— Elasticsearch ?倒排索引?这都是什么?
liuzhihang前言
革命同志是块砖,哪里需要哪里搬!这不,老大发话,要我在组内做一个 Elasticsearch 技术分享。这不话题一转,开始看起来 ES 了。虽然很久之前用过 ELK 做过日志监控系统,但是毕竟时隔已久,还是得从头看起。当然手头的活也不能停,话不多说,开始分享。先看看什么是 ES?
什么是ES
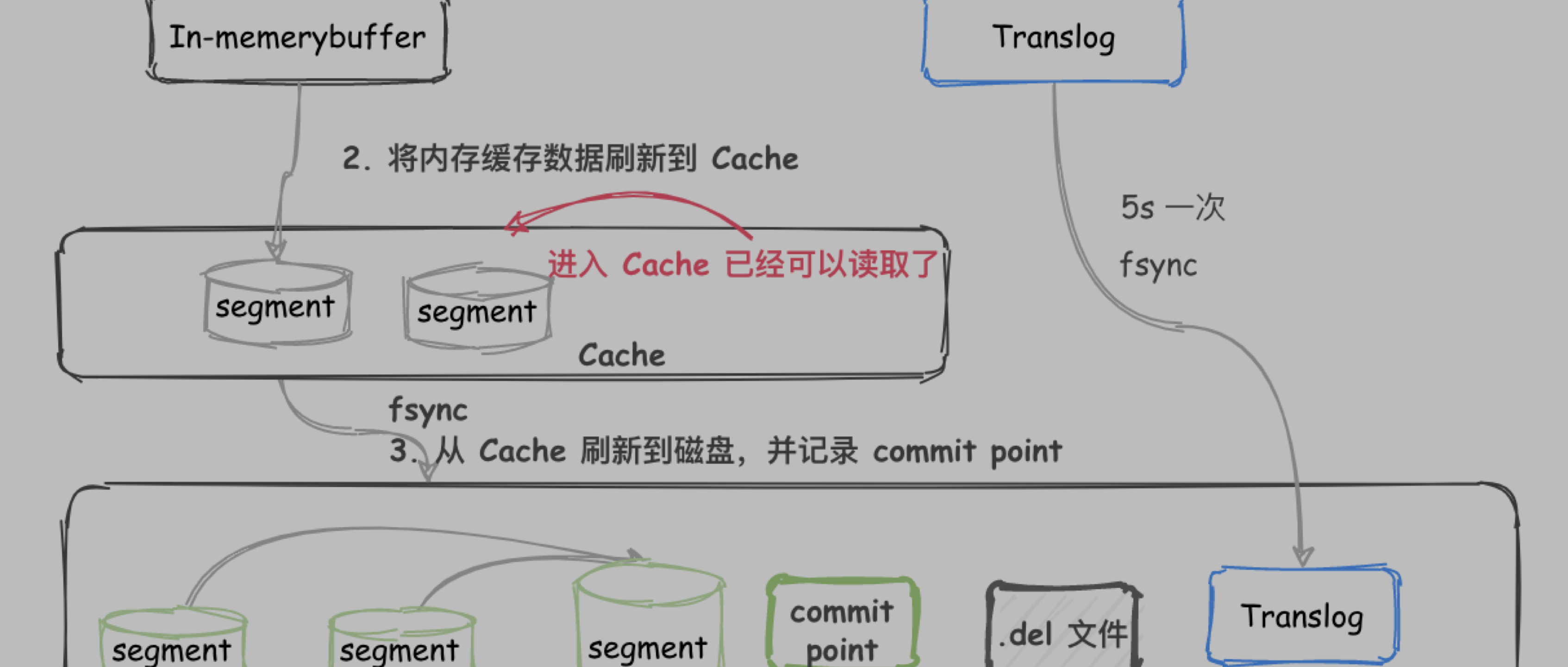
Elasticsearch 是分布式搜索和分析引擎。
Elasticsearch 为所有类型的数据提供**近实时(near real-time)**的搜索和分析。
常用场景:
- 网站搜索
- ELK 日志采集,存储,分析
- 地理信息系统分析
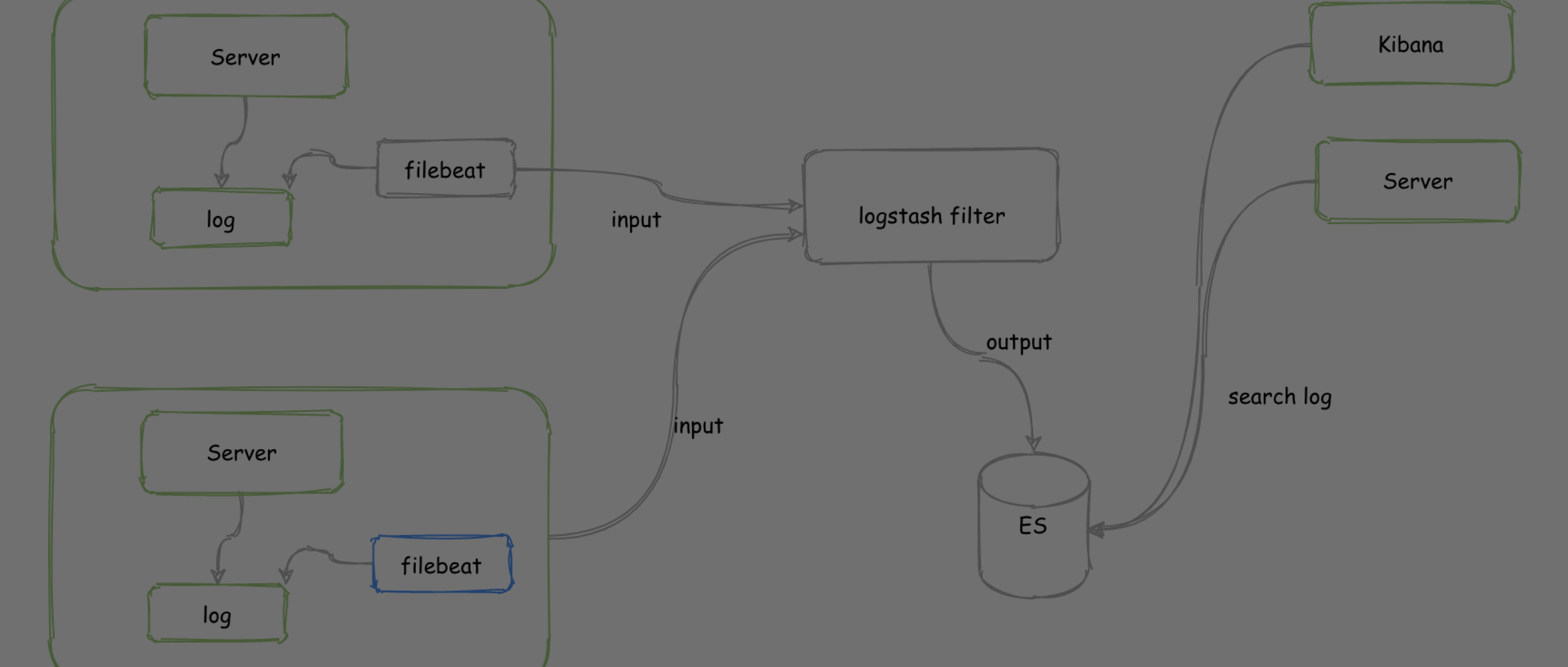
像下图中使用的设计:

特点:
- ES是一个分布式文档存储,存储的数据都是序列化为 JSON documents 。
- 使用倒排索引存储数据,倒排索引比较适合全文本搜索。
- 基于Apache Lucene搜索引擎库,可以存储,检索文档及元数据。
- 支持 JSON 样式的查询语言——Query DSL,也支持 SQL 样式的查询。
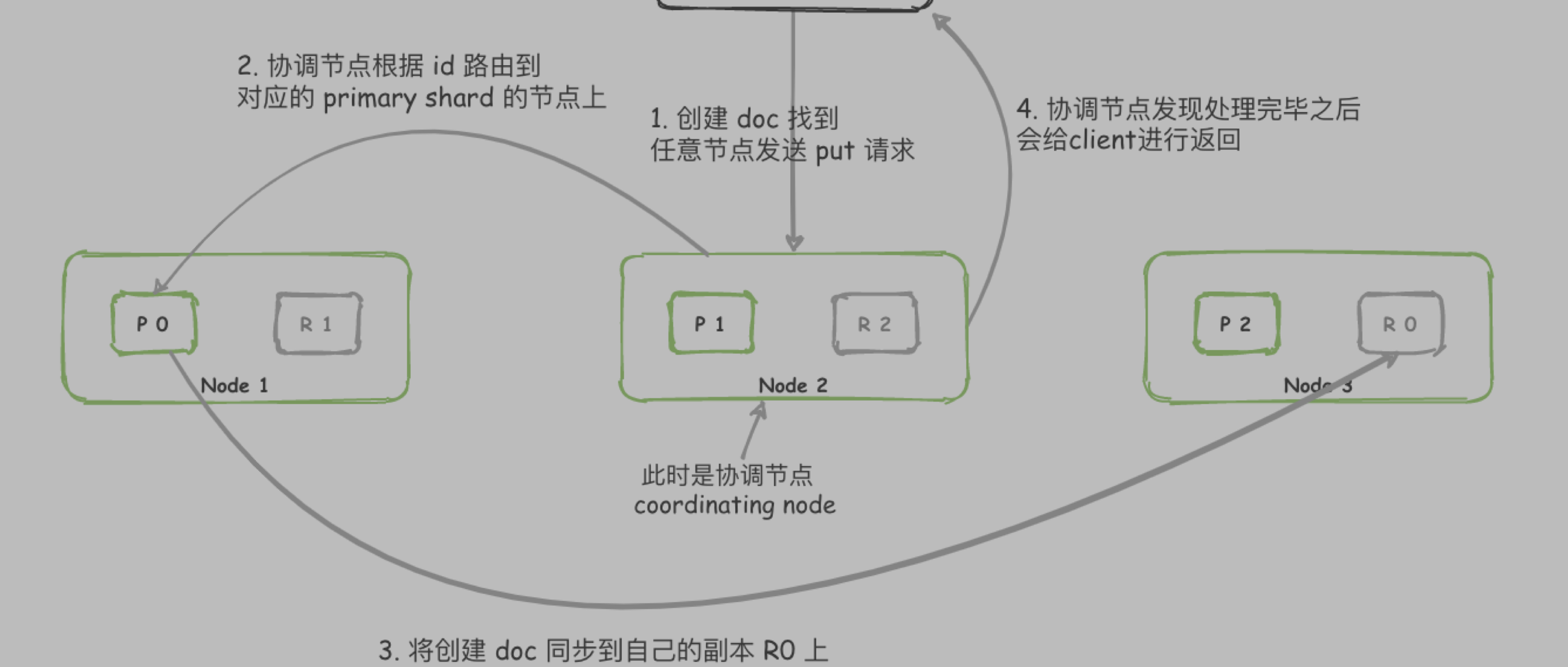
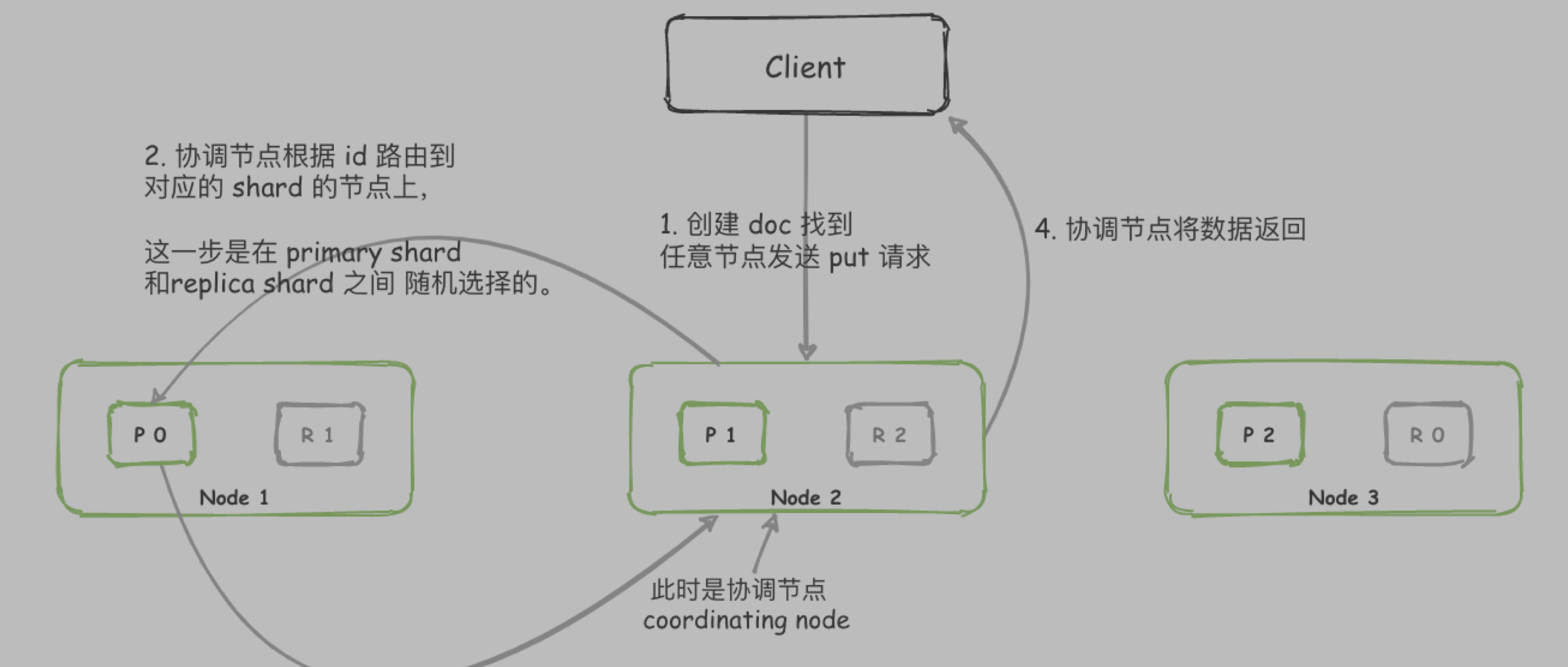
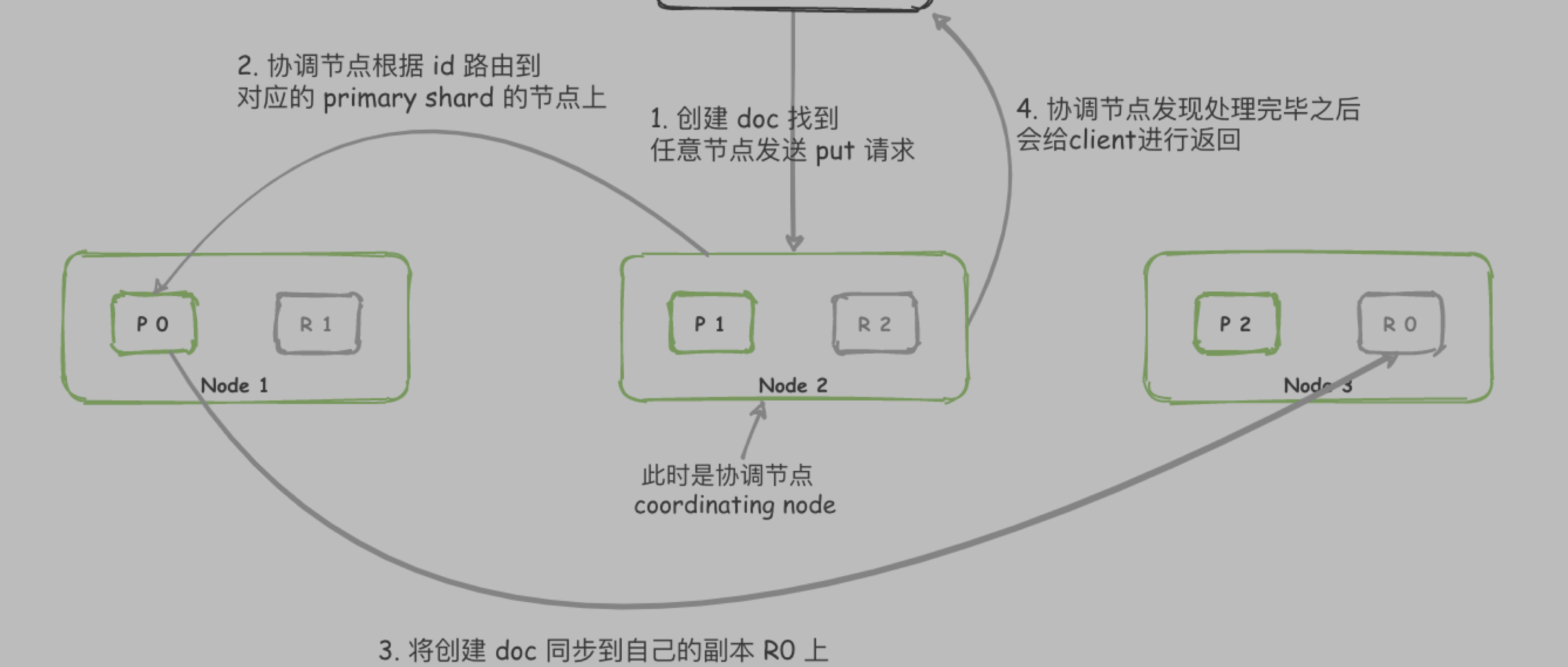
- 集群部署,易于扩展。节点(node)分片(shard),将新的 node 添加到集群时,ES 会自动迁移 shard 到新 node 上,重新平衡集群。
- shard 分为两种 主分片(primary shard)和 副本分片 (replica shard)
- replica shard 存放的是 primary shard 的冗余副本 —— 可以防止集群故障,数据丢失,同时可以提高搜索或检索速度。
- 在创建索引时 primary shard 数量是固定的,而replica shard 数量是可以更改的。
- 分片由索引配置,分片越多,维护索引则开销则越大,分片大小越大,则 ES 在增减节点重新平衡集群时,分片移动时间越长。
- 集群恢复: 跨集群复制 (CCR),可以自动将索引从主集群同步到热备份的辅助远程集群。
什么是倒排索引?
倒排索引也可以成为反向索引。
作为开发咱们经常接触到的就是 MySql,假设有一堆技术书籍,并且已经编上号。
- Java 并发编程之美
- Java 开发手册
- 深入分布式缓存
- Java 并发程序设计
- 算法
- 数据结构与算法
- 如果放在 MySql 里面就是这样
| id | book_name |
|---|---|
| 1 | Java 并发编程之美 |
| 2 | Java 开发手册 |
| 3 | 深入分布式缓存 |
| 4 | Java 并发程序设计 |
| 5 | 算法 |
| 6 | 数据结构与算法 |
此时我想查询所有关于 并发 的书籍。
1 | select * from table_book where book_name like %并发%; |
然后会开始遍历表格,查找到 1和4两条记录。
- 如果是倒排索引处理的话
首先会将每个名称进行分词,比如 Java 并发编程之美 会被分为 Java 并发 编程 之 美。
分词结束之后按照词关联书籍的编号。
| term | ids |
|---|---|
| Java | 1、2、4 |
| 并发 | 1、4 |
| 编程 | 1 |
| 算法 | 5、6 |
| 分布式 | 3 |
| … | … |
在倒排索引中搜索并发,然后进行检索,就很容易定位到关于并发书籍的编号。
那什么是 Lucene?
Lucene 可以理解为一个开源的、高性能、可伸缩的信息搜索库。使用 Java 开发,封装了各种倒排索引和搜索的API。相当于一个组件。
而 ES 就是在 Lucene 之上进行的开发,从而可以高可用、集群部署、故障迁移、备份容灾等。
总结
就这么多,先知道个 ES 是干嘛的。后续再慢慢看、慢慢总结。

喜欢这篇文章的人也看了

评论
匿名评论隐私政策
✅ 你无需删除空行,直接评论以获取最佳展示效果