前言
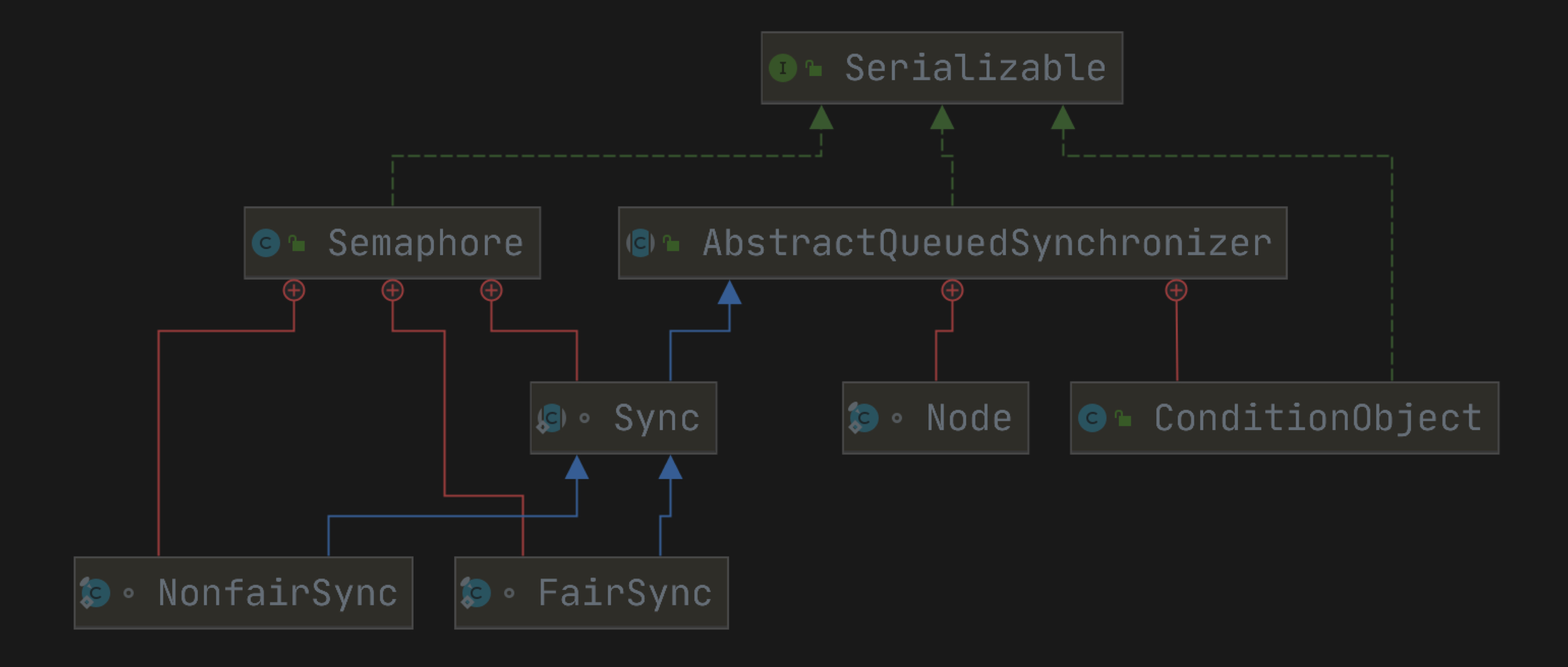
在 JUC 中线程同步器除了 CountDownLatch 和 CycleBarrier ,还有一个叫做 Semaphore (信号量),同样是基于 AQS 实现的。下面来看看信号量的内部原理。
介绍
一个计数信号量。 从概念上讲,信号量维护了一组许可。 如果有必要,在许可可用之前调用 acquire 方法会被阻塞,直到许可证可用。 调用 release 方法会增加了一个许可证,从而释放被阻塞的线程。
声明时指定初始许可数量。
调用 acquire(int permits) 方法,指定目标许可数量。
调用 release(int permits) 方法,发布指定的许可数量。
在许可数量没有到达指定目标数量时,调用 acquire 方法的线程会被阻塞。
基本使用
12345678910111213141516171819202122232425262728293031323334353637public class SemaphoreTest1 { private static final Semaphore SEMAPHORE = new Semapho ...
前言
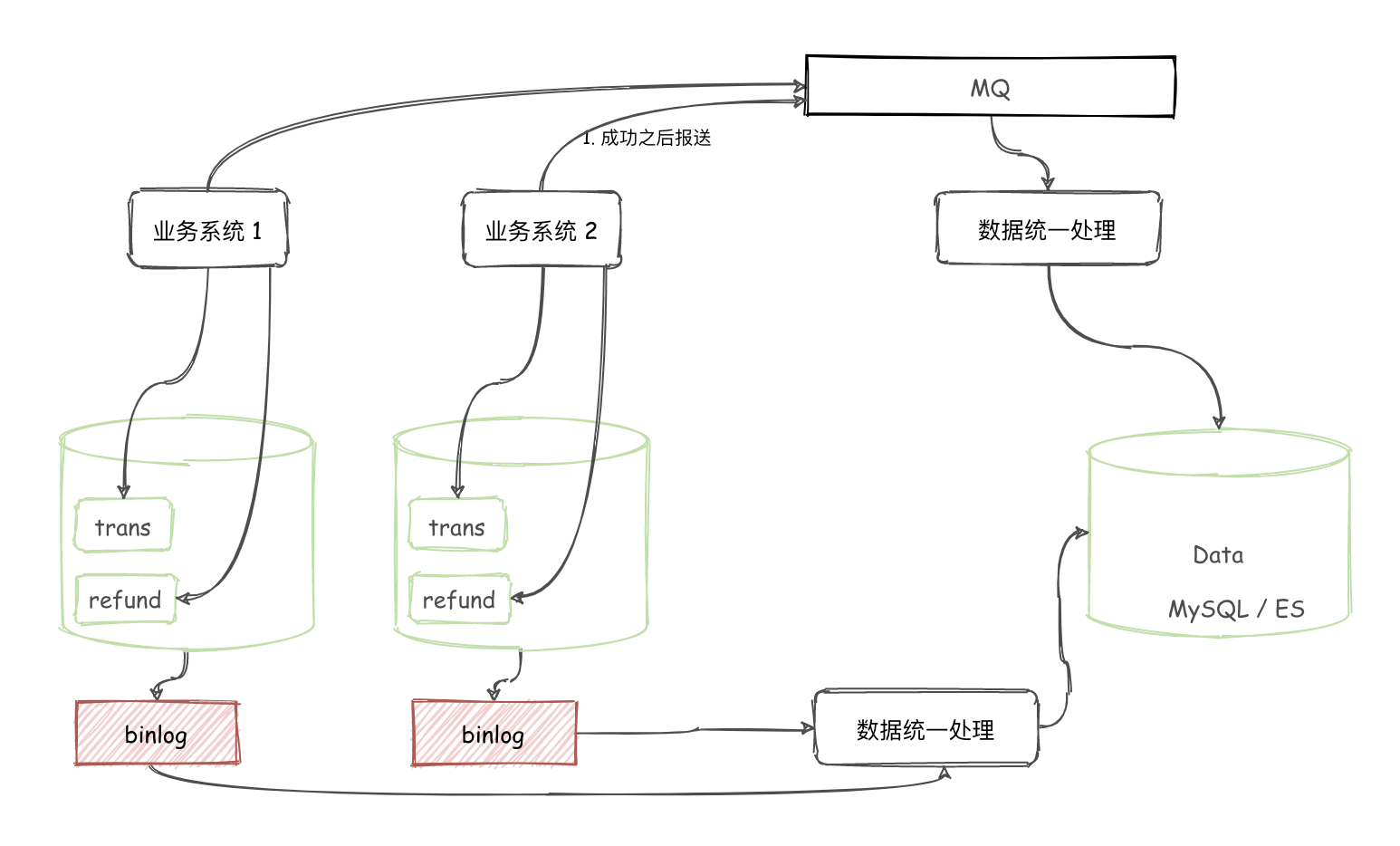
近期做新项目,在设计表结构的时候,突然想起来之前面试的时候遇到的一个问题,那时候也是初出茅庐,对很多东西一知半解(当然现在也是),当时那个小哥哥问我为什么交易和退款要拆成两个表?是基于什么考虑?有什么好处和优点么?
背景
那是一个风和日丽的下午,当然,风和日丽的下午应该配点其他的形容词,实在是我才疏学浅,只能用这个词充当了下开头…… (此处省略小五千字)
赶紧进入正文!
因为之前一直做聚合支付,而在使用过程中,也是支付和退款表拆开的,一直这么用,并没有觉得不妥。
比如一个交易表基本就是这样的:
字段
类型
含义
id
bigint
主键 id
trans_id
varchar
交易订单号
trans_amount
bigint
订单金额
trans_status
tinyint
交易状态
……
……
……
create_time
datetime
创建时间
update_time
datetime
更新时间
退款表是这样子的:
字段
类型
含义
id
bigint
主键 id
refund_id
varchar
...
前言
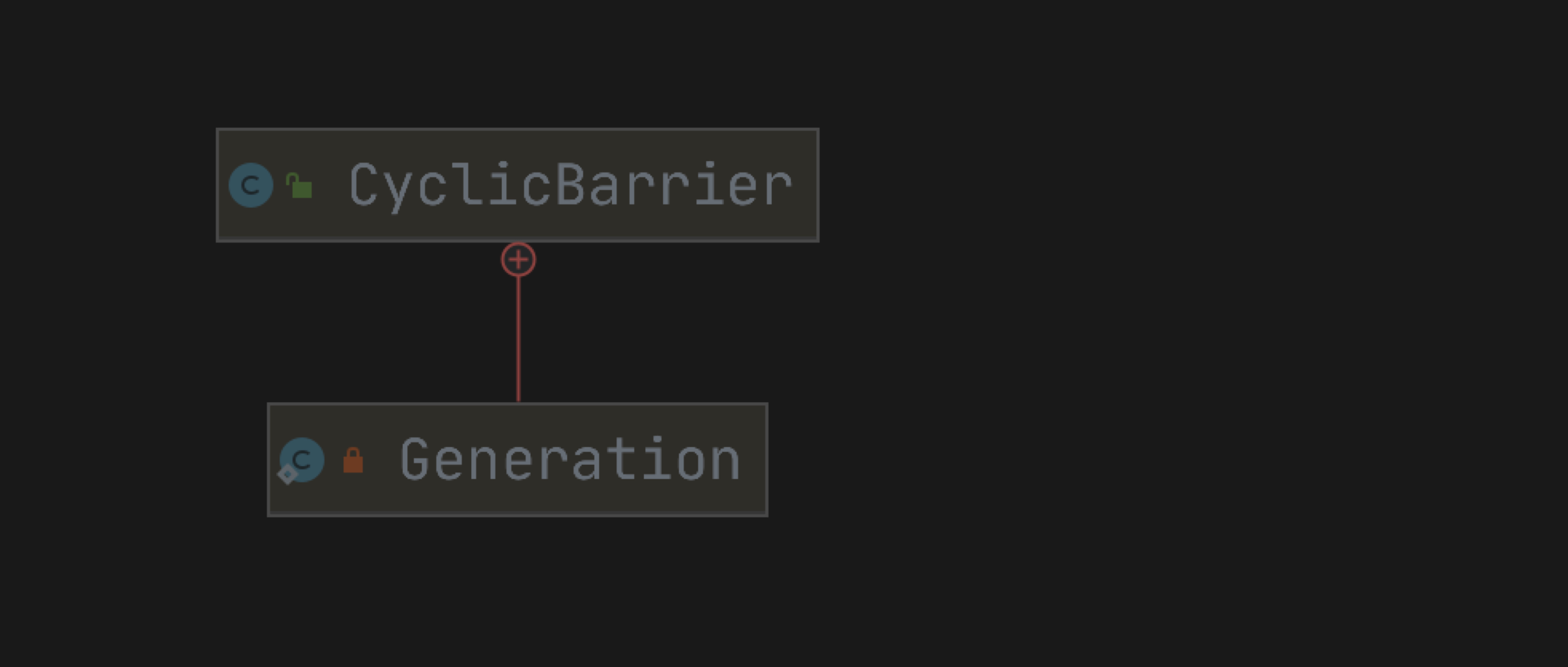
看完 CountDownLatch 正准备表示一番,突然看到了一个 CyclicBarrier —— 回环屏障。沃特?回环还屏障?说比 CountDownLatch 要多一个回环,那咱可得瞧一瞧,看一看了!
介绍
一个同步辅助,它允许一组线程的所有等待彼此达成共同屏障点。
CyclicBarrier 在涉及固定线程数且必须等待彼此的程序非常有用。
该屏障被称为回环屏障 ,因为它在等待的线程被释放后可以被重新利用。
CyclicBarrier 支持一个可选的 Runnable 命令,该命令在障碍中的最后一个线程到达之后,但在释放任何线程之前,每个屏障点运行一次。
此屏障操作对于在任何一方继续之前更新共享状态很有用。
通过上面的源码注释基本可以得出以下结论:
CyclicBarrier 和 CountDownLatch 类似,但它是一组线程等待,直到在其他线程中执行的一组操作完成为止。
CountDownLatch 是计数递减,结束后再调用 await 或者 countdown 都会立即返回,但是 CyclicBarrier 可以重置屏障。
CyclicBarrier 还可以 ...

前言
之前推了一篇文章《十张图带大家看懂 ES 原理 !明白为什么说:ES 是准实时的!》,很多小伙伴都比较好奇在文章中的图是用的什么画图软件?看那么明显的手绘风格,当然是手画的啦!(开玩笑),其实我用的是 draw.io ,下面分享我的画图软件 —— draw.io 。
为什么需要画图?
俗话说:“一图顶百字!”,好吧!这是我现想的俗话。
在新项目开发,技术分享,阅读代码笔记,或者面试的时候,画个流程图,架构图等等,比较直观,便于理解等。优点啥的就不多介绍了,这里主要介绍我的画图软件。
基本要求
免费
使用方便
支持离线使用
用过的其他软件
Visio:使用方便,在最开始的时候就是使用 Visio,不过只能在 Win 系统上使用。
ProcessOn:在线版,使用方便,很简洁。个人免费,不过限制文件数量。
OmniGraffle:Mac 客户端,收费,有很多功能,不过对我来说有点玩不熟练。
语雀:语雀也支持画简单的流程图。
其他一些,暂时没想起来的。
体验了很多画图软件,最后还是(暂时)选择了 draw.io 。 原因很简单,支持多平台(网页/Win/Mac/Linux ...
前言
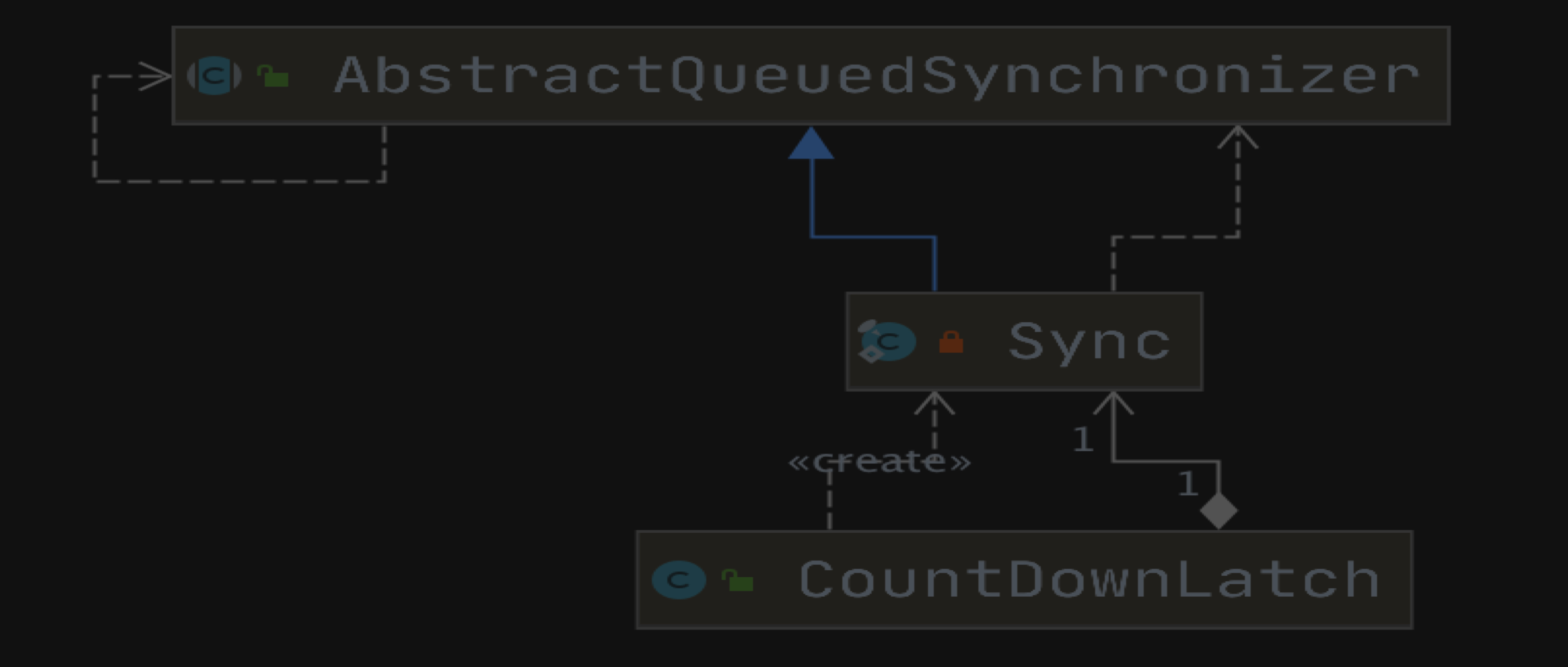
CountDownLatch 一个同步辅助工具,同样是基于 AQS 实现,本篇文件主要是介绍 CountDownLatch 的使用,以及源码。
介绍
一个同步辅助工具,允许一个或多个线程等待,直到在其他线程中执行的一组操作完成为止
一个 CountDownLatch 初始化为给定计数。 在 await 方法阻塞,调用 countDown 方法会减少计数直到达到零,此后所有等待的线程被释放,任何后续调用 await 都会立即返回。 这是一次性的现象 - 计数不能复位。 如果你需要一个版本重置计数,请考虑使用CyclicBarrier 。
CountDownLatch 是一种通用的同步工具,可用于多种用途。
用作一个简单的开/关锁存器,或者门:所有线程调用await在门口等待,直到被调用 countDown 的线程打开。
初始化计数为 N ,用一个线程等待,直到 N 个线程完成某项操作,或某些动作已经完成 N 次。
CountDownLatch 一个有用的属性是,它不要求调用 countDown 线程等待计数到达零之前继续,它只是阻止任何线程通过await ,直到所有线程可 ...
前言
说到 Elasticsearch ,其中最明显的一个特点就是 near real-time 准实时 —— 当文档存储在Elasticsearch中时,将在1秒内以几乎实时的方式对其进行索引和完全搜索。那为什么说 ES 是准实时的呢?
Lucene 和 ES
Lucene
Lucene 是 Elasticsearch所基于的 Java 库,它引入了按段搜索的概念。
Segment: 也叫段,类似于倒排索引,相当于一个数据集。
Commit point:提交点,记录着所有已知的段。
Lucene index: “a collection of segments plus a commit point”。由一堆 Segment 的集合加上一个提交点组成。
对于一个 Lucene index 的组成,如下图所示。
Elasticsearch
一个 Elasticsearch Index 由一个或者多个 shard (分片) 组成。
而 Lucene 中的 Lucene index 相当于 ES 的一个 shard。
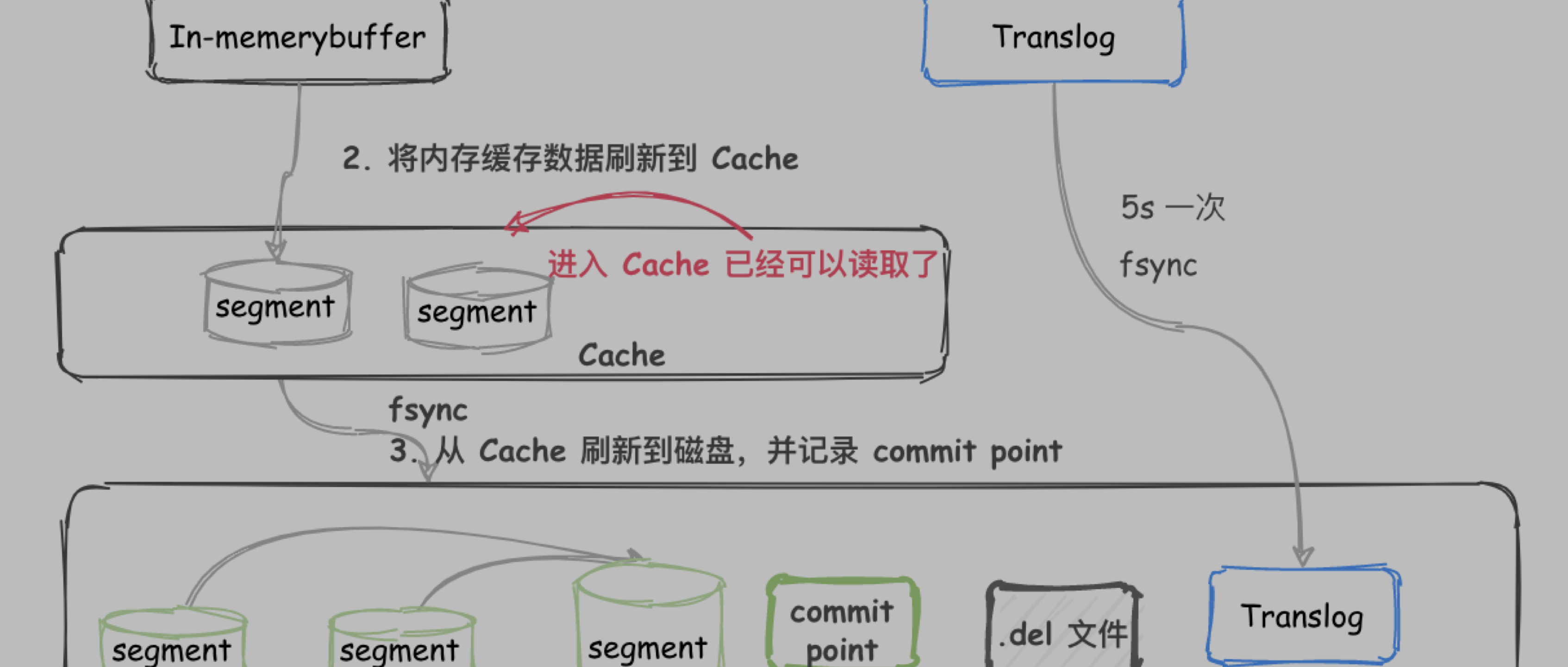
写入过程
写入过程 1.0 (不完善)
不断将 Docum ...
前言
ES 使用过程中常用的就是查询以及检索,那查询和检索的过程,什么样的呢?
查询流程
1GET my-index/_doc/0
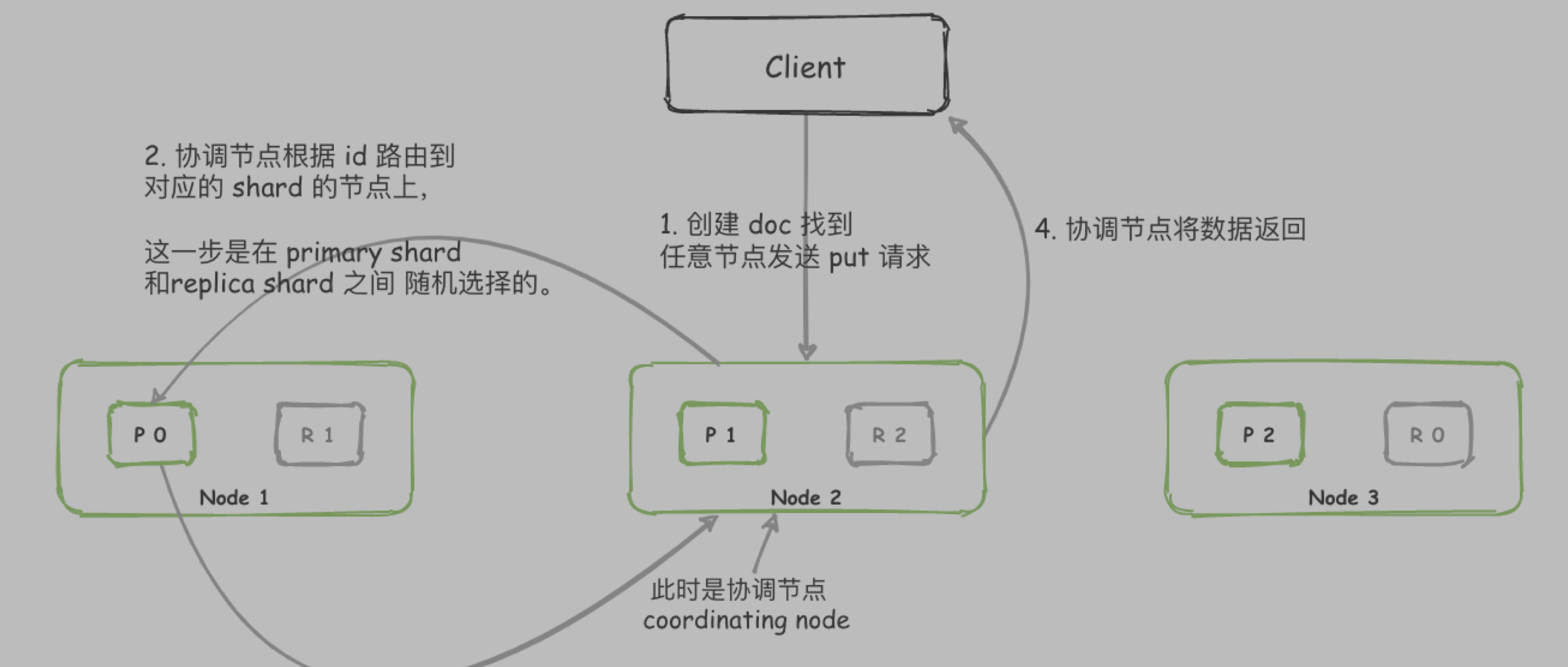
Client 将请求发送到任意节点 node,此时 node 节点就是协调节点(coordinating node)。
协调节点对 id 进行路由,从而判断该数据在哪个shard。
在 primary shard 和 replica shard 之间 随机选择一个,请求获取 doc。
接收请求的节点会将数据返回给协调节点,协调节点会将数据返回给Client。
可以通过 preference 参数指定执行操作的节点或分片。默认为随机。
检索流程
1GET /my-index/_search
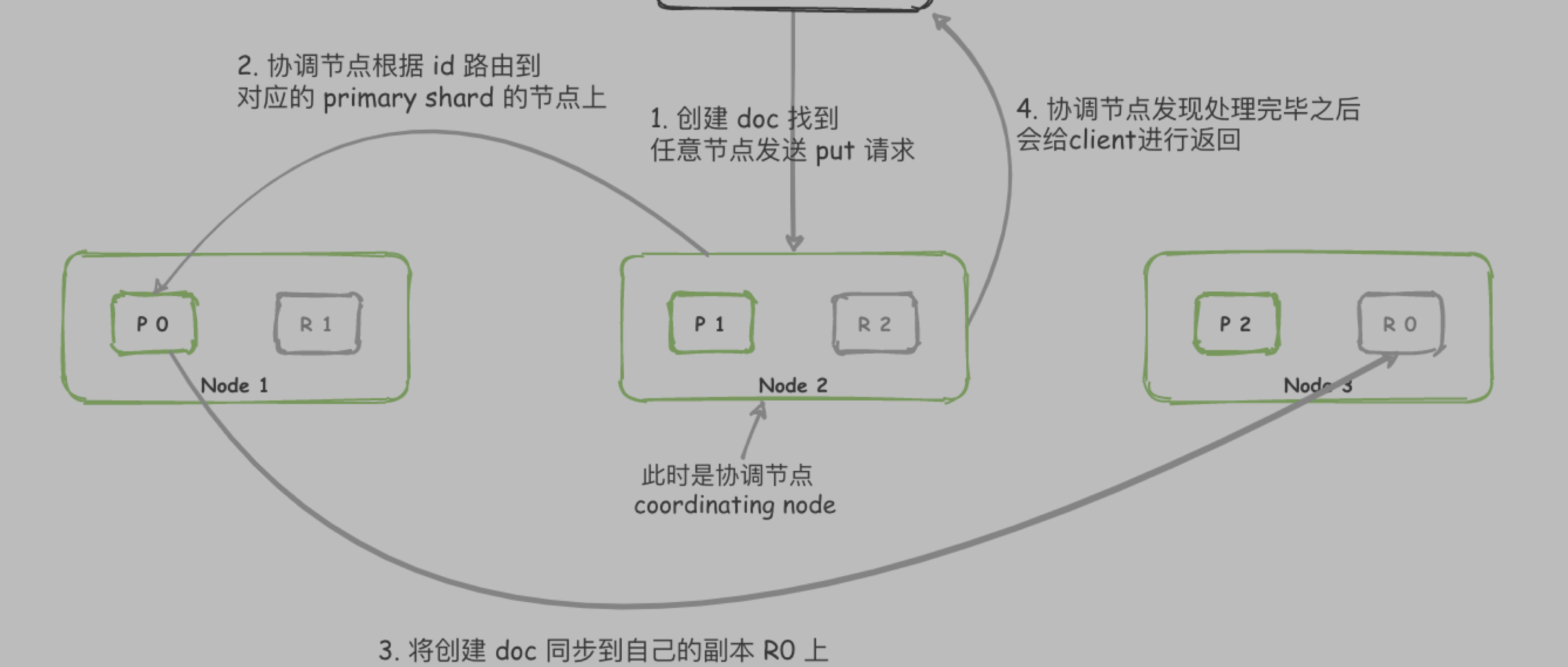
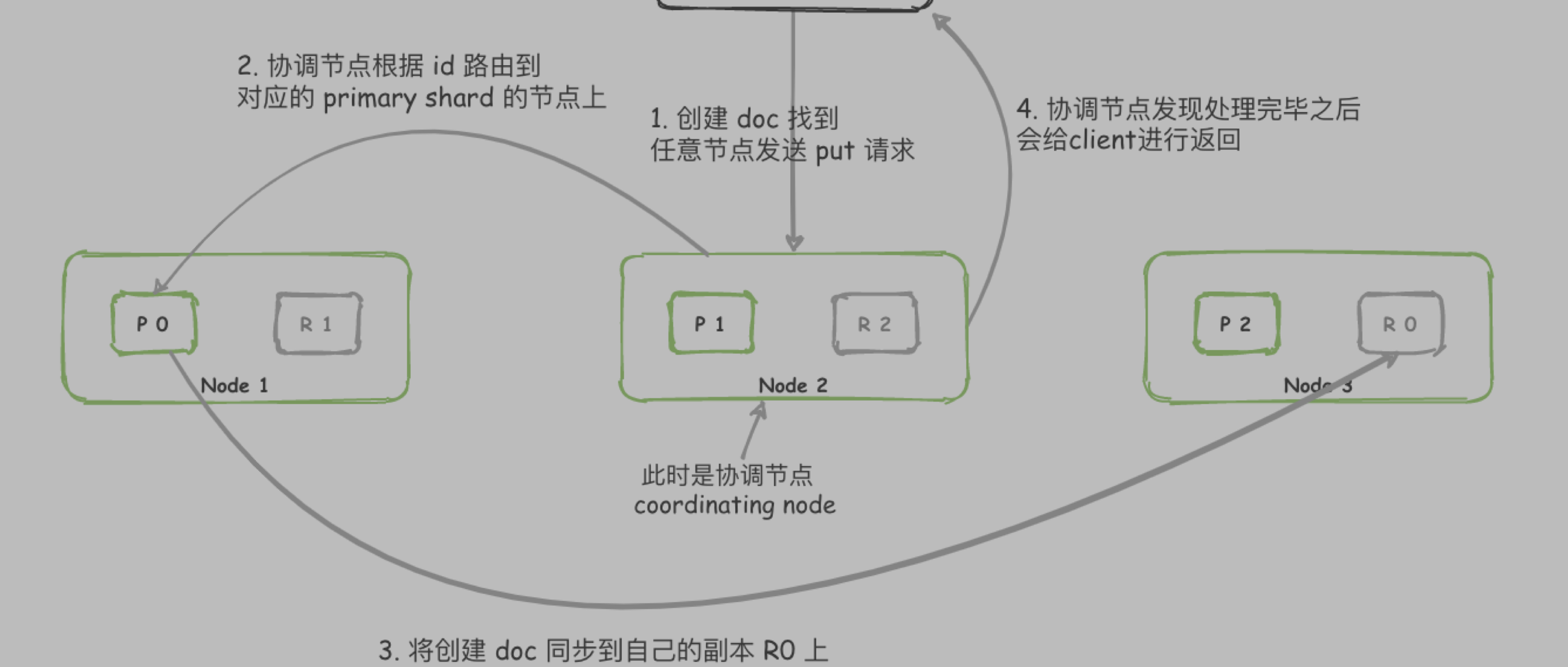
Client 将请求发送到任意节点 node,此时 node 节点就是协调节点(coordinating node)
协调节点进行分词等操作后,去查询所有的 shard (primary shard 和 replica shard 选择一个)
所有 shard 将满足条件的数据 id 排序字段 等信息返回给路由节点
路由节点重新进行排序,截取数据后,获取 ...
前言
在前面已经介绍了 ES 中常用的一些名词,知道了数据是存储在 shard 中的,而 index 会映射一个或者多个 shard 。那这时候我要存储一条数据到某个索引下,这条数据是在哪个 index 下的呢?
ES 演示
一切按照官方教程使用 三条命令,在本机启动三个节点组装成伪集群。
12345~ % > ./elasticsearch~ % > ./elasticsearch -Epath.data=data2 -Epath.logs=log2~ % > ./elasticsearch -Epath.data=data3 -Epath.logs=log3
创建索引
12345678910curl -X PUT "localhost:9200/my-index-000001?pretty" -H 'Content-Type: application/json' -d'{ "settings": { "index": { ...
前言
看完什么是 Elasticsearch 以及了解到了倒排索引的概念,下面就熟悉下 ES 中常用的一些名词。
常用术语
名词
解释
cluster
一个或者多个 node 指定相同的 cluster name,则它们会组成集群,并且自动选举 master,以及在故障时自动选举。
node
节点是属于集群的Elasticsearch的运行实例 。在启动时,节点将使用单播来发现具有相同集群名称的现有集群,并将尝试加入该集群。
index
类似关系数据库的表,映射一个或者多个主分片,同时拥有零个或多个副本分片。
index alias
索引别名是用于引用一个或多个现有索引的辅助名称。大多数Elasticsearch API接受索引别名代替索引名称。
mapping
每个 index 都有一个 mapping ,定义一个 type 以及许多索引范围的设置。mapping 可以明确定义,也可以在为文档建立索引后自动生成。
shard
分片是单个Lucene实例。最小的工作单位,由Elasticsearch自动管理。索引是指向主分片和副本分片的逻辑命名空 ...

前言
革命同志是块砖,哪里需要哪里搬!这不,老大发话,要我在组内做一个 Elasticsearch 技术分享。这不话题一转,开始看起来 ES 了。虽然很久之前用过 ELK 做过日志监控系统,但是毕竟时隔已久,还是得从头看起。当然手头的活也不能停,话不多说,开始分享。先看看什么是 ES?
什么是ES
Elasticsearch 是分布式搜索和分析引擎。
Elasticsearch 为所有类型的数据提供**近实时(near real-time)**的搜索和分析。
常用场景:
网站搜索
ELK 日志采集,存储,分析
地理信息系统分析
像下图中使用的设计:
特点:
ES是一个分布式文档存储,存储的数据都是序列化为 JSON documents 。
使用倒排索引存储数据,倒排索引比较适合全文本搜索。
基于Apache Lucene搜索引擎库,可以存储,检索文档及元数据。
支持 JSON 样式的查询语言——Query DSL,也支持 SQL 样式的查询。
集群部署,易于扩展。节点(node)分片(shard),将新的 node 添加到集群时,ES 会自动迁移 shard 到新 nod ...
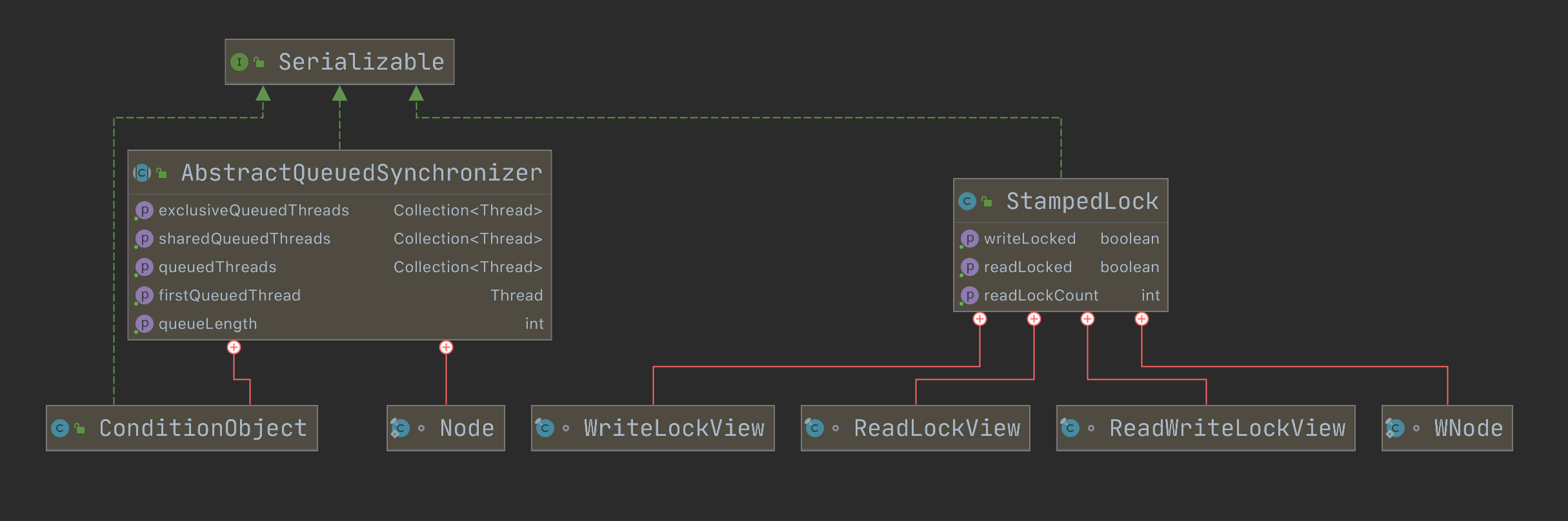
前言
在了解完 ReentrantLock 和 ReentrantReadWriteLock 之后,惊奇的发现 JUC 下还有一个 StampedLock 。 查阅资料发现是 JDK8 新增的一个锁。现在已经 JDK15 了,原谅我的孤陋寡闻,实在是业务开发中用的太少。那行吧,赶紧来看一下 StampedLock 到底是什么?为什么有了 ReentrantLock 和 ReentrantReadWriteLock 之后还要设计一个 StampedLock ?
介绍
往期回顾
在介绍 StampedLock 之前还是先看一下 ReentrantLock 和 ReentrantReadWriteLock。
ReentrantLock:互斥锁,同时只有一个线程可以持有。支持锁重入。
ReentrantReadWriteLock:读写锁,分为读锁和写锁,支持重入。其中读读共享,写写独占,读写互斥,写读互斥。支持锁降级,线程获取写锁后可以降级为读锁。适合读多写少的场景。
那为什么要设计 StampedLock 呢?先来看一下源码上的注释:
StampedLock
基于功能的锁,具有三种模式 ...

IDEA
未读
在开发Toolkit过程中查阅相关资料和阅读其他开源项目总结的一些常用API.
整体内容来源于网络, 以及自己使用开发Toolkit过程中使用到的.
总结的不到位的地方欢迎指正.
AnAction操作
创建Action集成AnAction并实现其actionPerformed方法. 在方法中可以获取到AnActionEvent对象. 代码如下:
1234567891011121314151617public class JsonFormatAction extends AnAction { @Override public void actionPerformed(AnActionEvent event) { // 获取当前project对象 Project project = event.getData(PlatformDataKeys.PROJECT); // 获取当前编辑的文件, 可以进而获取 PsiClass, PsiField 对象 PsiFile psiFile = event. ...




