Elasticsearch 数据写入流程

Elasticsearch 数据写入流程
liuzhihang简单流程
-
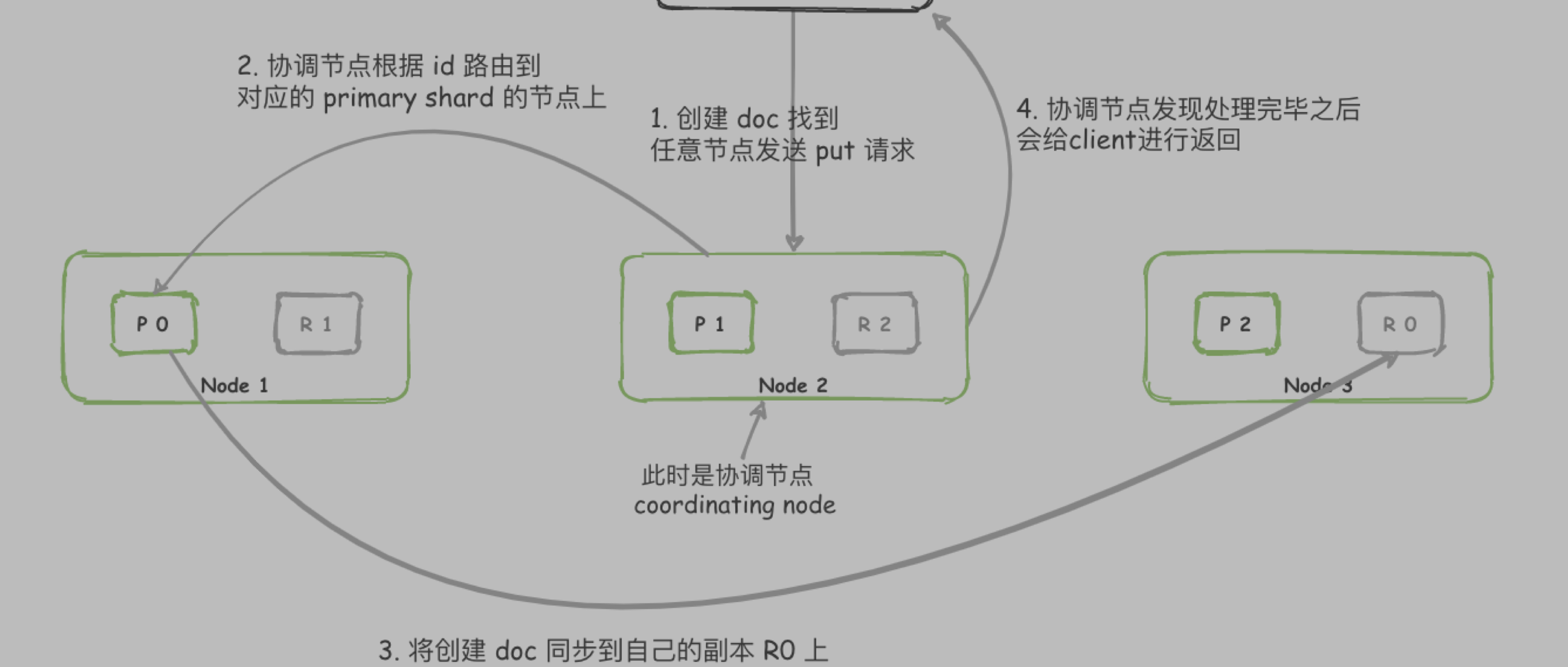
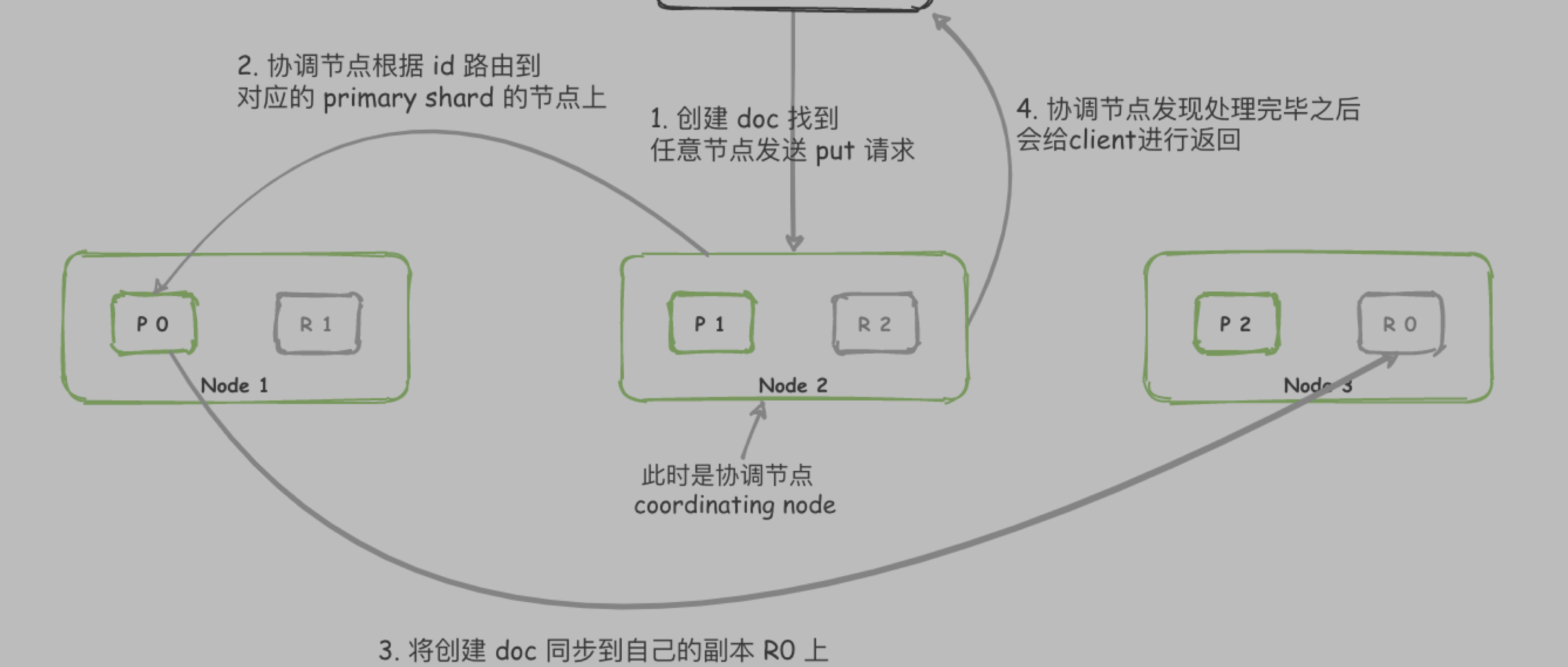
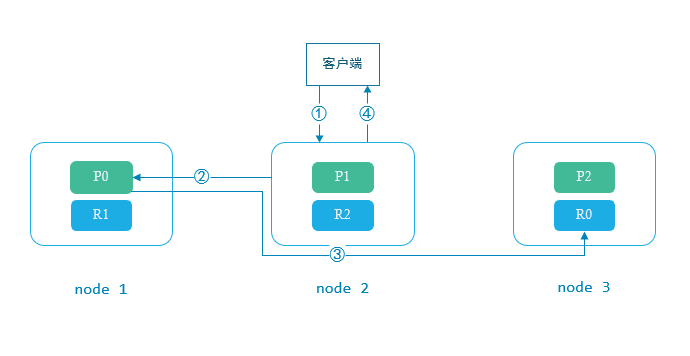
客户端随机选择一个node发送数据, 此时该node为协调节点(coordinating node)
1.1. coordinating node 通过 _id计算出该document在哪个shard上, 假设为shard0, 计算方式如下:hash(_id) % number_of_primary_shards
1.2. node 根据 cluster state 获取到 shard0 在 node1 上
- 将消息发送到 node1 的 P0 上
- P0 收到数据后, 将数据同步到 自己的 replica shard R0上
- P0 和 R0 都处理完毕, 才会返回客户端成功
Px 为 primary shard
Rx 为 replica shard
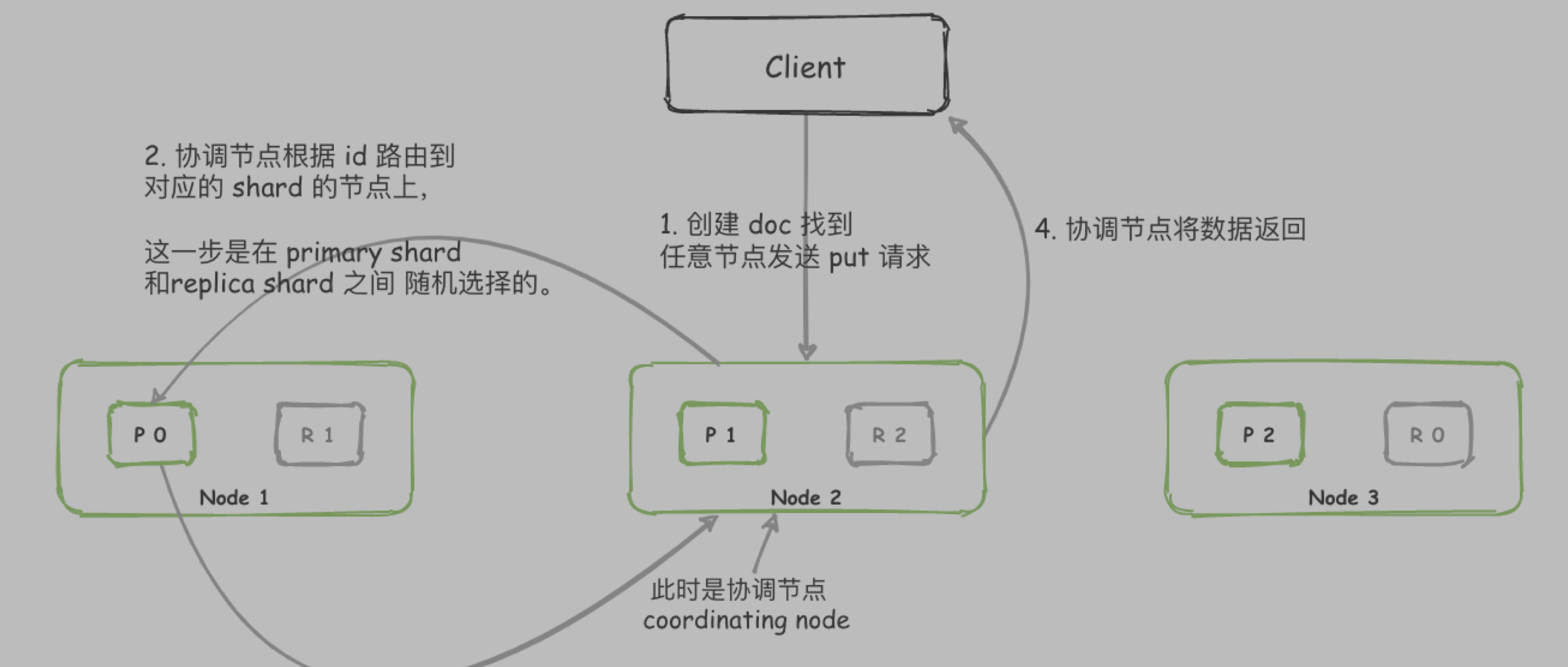
当客户端请求为查询时, 路由到任意 shard(primary shard 或者 replica shard) 查询到数据即可返回.
详细流程
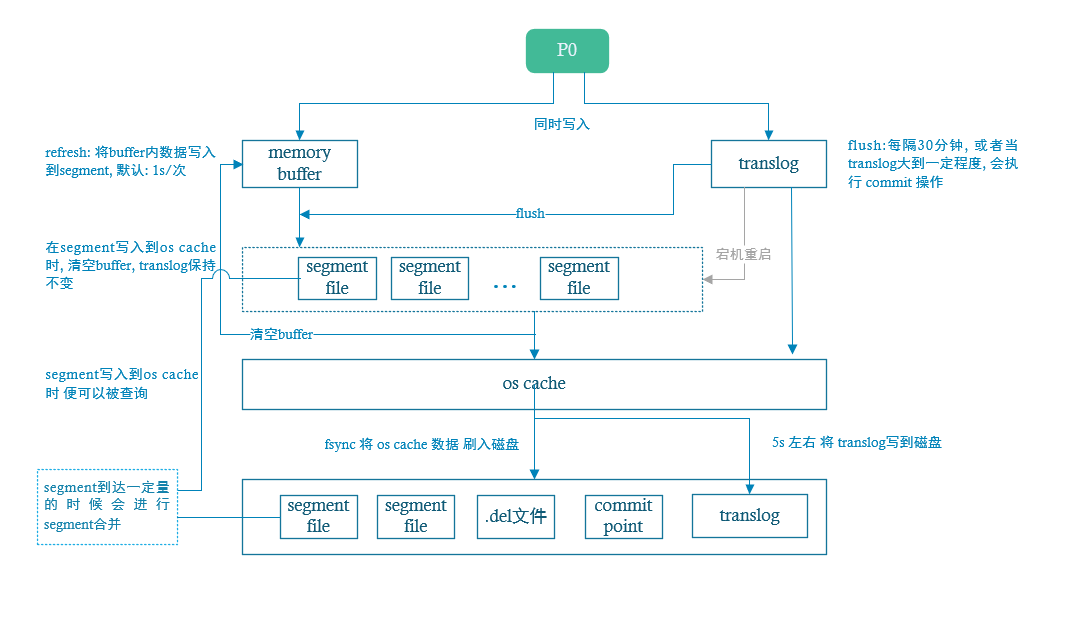
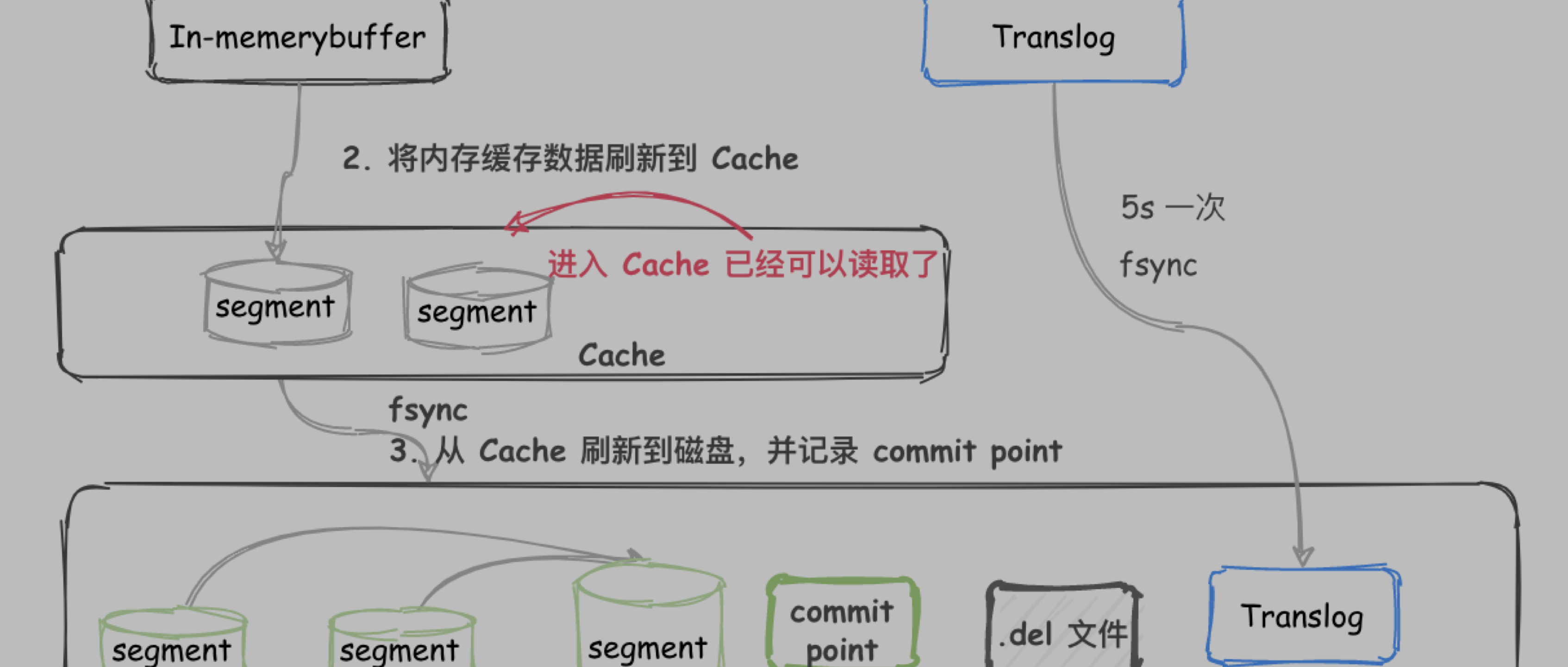
- P0收到document, 同时将数据写入到 内存buffer和translog中
- 每隔1s或buffer满时, buffer中的数据会 refresh 到segment中, 而后进入os cache, 一旦segment进入到 cache中,其中的数据, 则可以被搜索到
refresh 时间可以手动设置, 也可以手动触发 refresh
- 清空buffer, translog不处理
- 重复1-3操作, translog不断增大, translog每隔30分钟,或大到一定量时, 会触发commit操作
- 将buffer中内容刷新到segment中, 并清空buffer
- 将一个commit point 写入到磁盘文件中, 标识此次commit 对应的 segment
- 执行 fsync 将 os cache 中的数据强制刷新到磁盘文件中
- 删除 translog 文件
删除和更新操作
在commit时, 如果操作为删除, 生成一个 .del文件, 其中将该document标记位deleted, 并不是真正的物理删除, 此时如果有查询请求, 会先查询 .del文件中是否有该记录, 如果有, 则回复不存在.
在commit时, 如果为更新操作, 则是将原document标记位deleted, 同时写入一条新数据
服务宕机重启, translog 日志作用
translog是先写入到 os cache中, 然后每隔5s写入到磁盘文件中, 假如服务宕掉, 可能会失去5s数据, 也可以修改写入磁盘的时机, 但是可能会影响性能
translog中记录的是数据操作信息, 在服务宕机重启时, 会读取translog磁盘文件, 然后将translog中的数据重新恢复到 segment中, 然后进行后续操作
segment merge 过程
segment 持续生成, 会导致 segment不断变多, 占用文件句柄, cpu资源等等
es后台有一个专门的程序负责合并segment, 将小的 segment 合成大的segment, 同时写一个commit point, 标识 新的segment file.
打开新的segment供查询使用, 删除旧的 segment
segment 合并过程中, 被标记位 deleted 的document 不会被合并. 即: 在合并 segment时, 才将 document 真正物理删除
合并的segment 可以使磁盘上已经commit的索引 也可以是内存中还未commit的索引